文 | HW君
本文为B站【V1】期的视频讲稿。
部分动态演示,请参考视频画面:
VR沉浸感的奥秘,人眼如何通过双目视差硬解深度信息【双目VR摄影#V1】
0. 双目VR摄影系列前言
做VR内容的博主常常会表达类似如下的观点。
在手机上看别人玩VR,和自己亲自上手玩VR,是两种截然不同的感受。
只有亲自戴上VR眼镜,才能感受到VR那种迷人的沉浸感。
那这种「VR沉浸感」,真的只能意会不可言传吗?
我并不是这样认为的。
「VR沉浸感」的奥秘,其实就在于人眼可以通过「双目视差」获取「深度信息」。
这一过程是在大脑里自动发生的,它涉及到一些心理机制,因此很多人并不能很好地描述 出来。
那么在这个视频里,我会帮大家梳理清楚,这个说不清道不明的「VR沉浸感」究竟是什么。
消失的模因,大家好,我是HW君。
欢迎来到【V1】期,也就是我们频道的新节目「双目VR摄影」的第1期。
【V系列】狭义上讨论的话题是,如何拍摄与制作「VR影像」。
广义上探讨的则是「摄影」「光学」「VR」这三个学科的交叉地带。
「双目VR摄影」是一种很新的事物,市面上缺乏对其基础性原理的讨论。
HW君希望自己能为这个领域增加一些内容,因此决定制作这个系列。
目前这个系列的暂定规划如下,当然后续肯定会有变动和调整。
【V1】人眼如何通过双目视差获取深度信息
【V2】鱼眼镜头快速入门
【V3】瞳距意味着什么
【V4】如何拍摄一个VR180视频
……
前几期我会把重点放在底层原理的讨论上,虽然会比较冗长和枯燥,但这才是市面上最欠缺的内容。
虽然我很清楚短平快的视频才是流量密码,但我个人还是希望能为这个领域留下一些有深度的内容。
而在搭建完基础的理论框架之后,我也会尝试去做一些大众更感兴趣的内容,例如具体的拍摄和后期等,这是之后的规划。
如果你期待的是这一部分,那么可能还需要再等几期。
而在梳理原理时,我会用到两本参考书籍。
一本是Wiley出版社的《光学系统手册》的第4卷,是一本英文书籍。
另一本是电子工业出版社的张以谟主编的《应用光学》第3版,是一本中文教材。

这两本都是大而全的入门读物,很适合像我这样的业余小白。
同时大家也都可以很容易地在网络上找到电子版。
我们在讲解原理时,会参考这两本书的数据和图表。
不过这里还是需要说明一下,我也只是一个业余的爱好者,希望大家能指出我视频里出现的错误,一起学习进步。
那在正式开始我们的【V1】期之前,那HW君也聊聊自己做这个系列的契机吧。
我好端端的一个民科,怎么突然就开始讲VR了呢?
在此之前,我曾做过2期关于VR的视频。
分别是【HW君随便聊】系列的【R6】和【R7】期。
其中【R6】提及了Pico Neo 3,【R7】则提及了PICO 4。
为什么会做这两期视频呢?
因为HW君所喜欢的「A-SOUL」在PICO的平台上有推流VR直播。
这两家刚合作的时候受到了各种嘲讽,很多不了解的人觉得,花钱买VR设备就只为看一个全景视频直播?那干嘛不在B站上看呢?
但实际上真正尝试过的A-SOUL观众,大多都觉得值回票价。
因为A-SOUL在PICO上的直播流是双画面的,它携带「深度信息」,这是看B站直播所获取不到的。
为此我做了视频来讨论这些观点。
而在入坑之后,我发现在「VR摄影」里,有一些我所追求的东西。
GoneMeme这个频道一直以来都会讨论一个话题。
人与人之间是很难互相沟通、互相理解的。
我们要如何将自己的所感所想,传递给另一个人。
而同时,我们又要如何去理解、感受另一个人的想法。
这是一个亘古的难题。
而VR是一种隔绝外界的显示设备,相比于手机电脑等「开放式屏幕」,VR更容易实现影像的标准化,从而确保信息传递的准确性。
并且VR是双目显示设备,它比手机电脑等2D屏幕多出一维深度信息。
因此在影像信息的传递中,它要比传统显示设备更有优势。
VR影像可以更好地做到,让观看者「见我所见,感我所感」。
这是非常艰难的事情,却也是人类所永恒追求的事情。
人际之间更好的信息传递,是GoneMeme一直以来都在探讨的课题。
因此做「双目VR摄影」的内容对我来说并非不务正业,而算是在原来追求与思考的道路上的一段延伸吧。
那【V系列】的前言就到这里。
接下来我们一起来梳理所谓的【VR沉浸感】,究竟是怎么一回事。
1. 立体视觉的产生机制
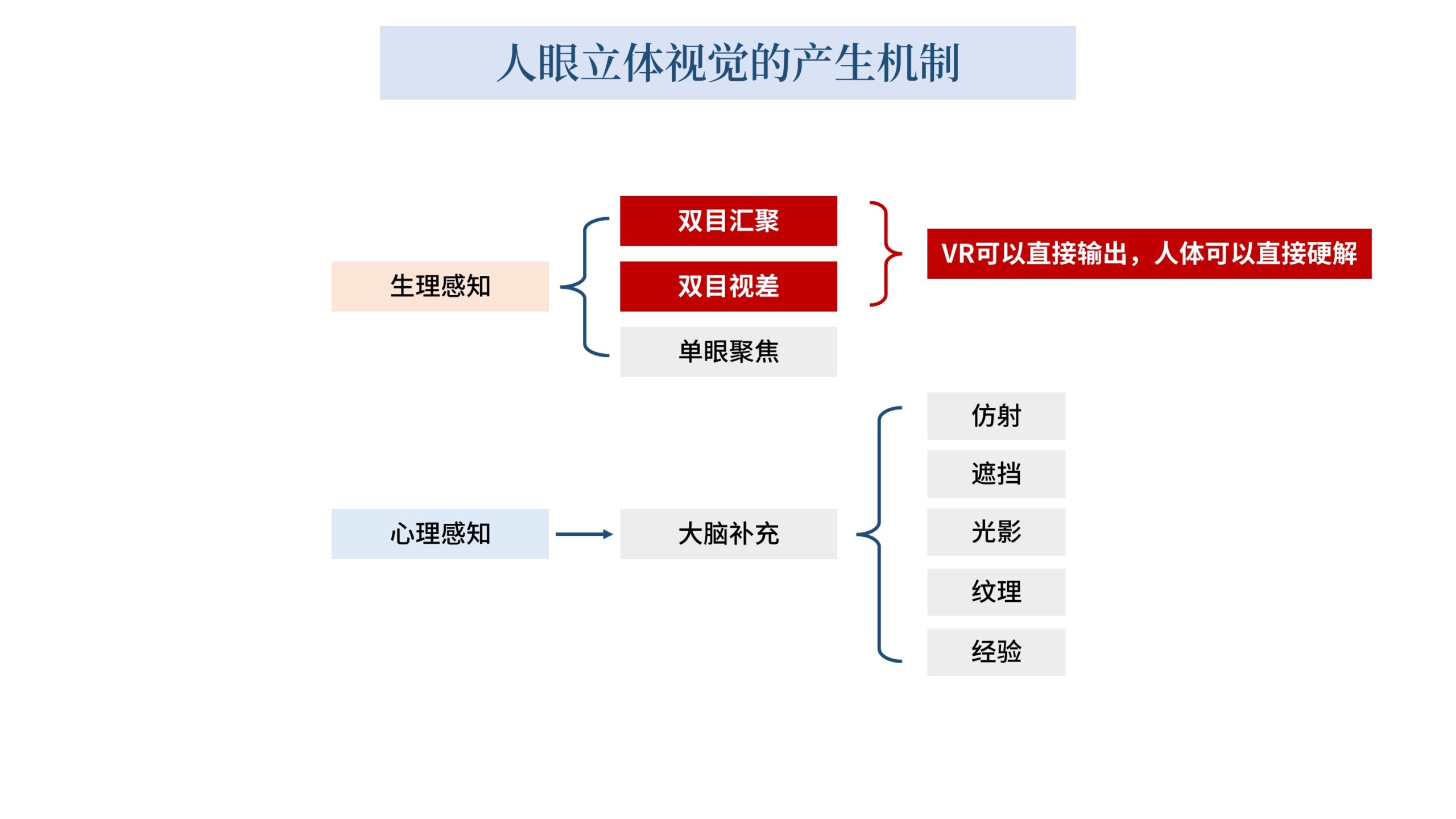
人类拥有「立体视觉」,可以感知画面中物体的深度信息。
这种「立体感」是由多种机制共同塑造的。
立体视觉的产生,其优先级从高到低,大致上按照如下顺序排列。
双目汇聚、双目视差、单眼聚焦、大脑补充。
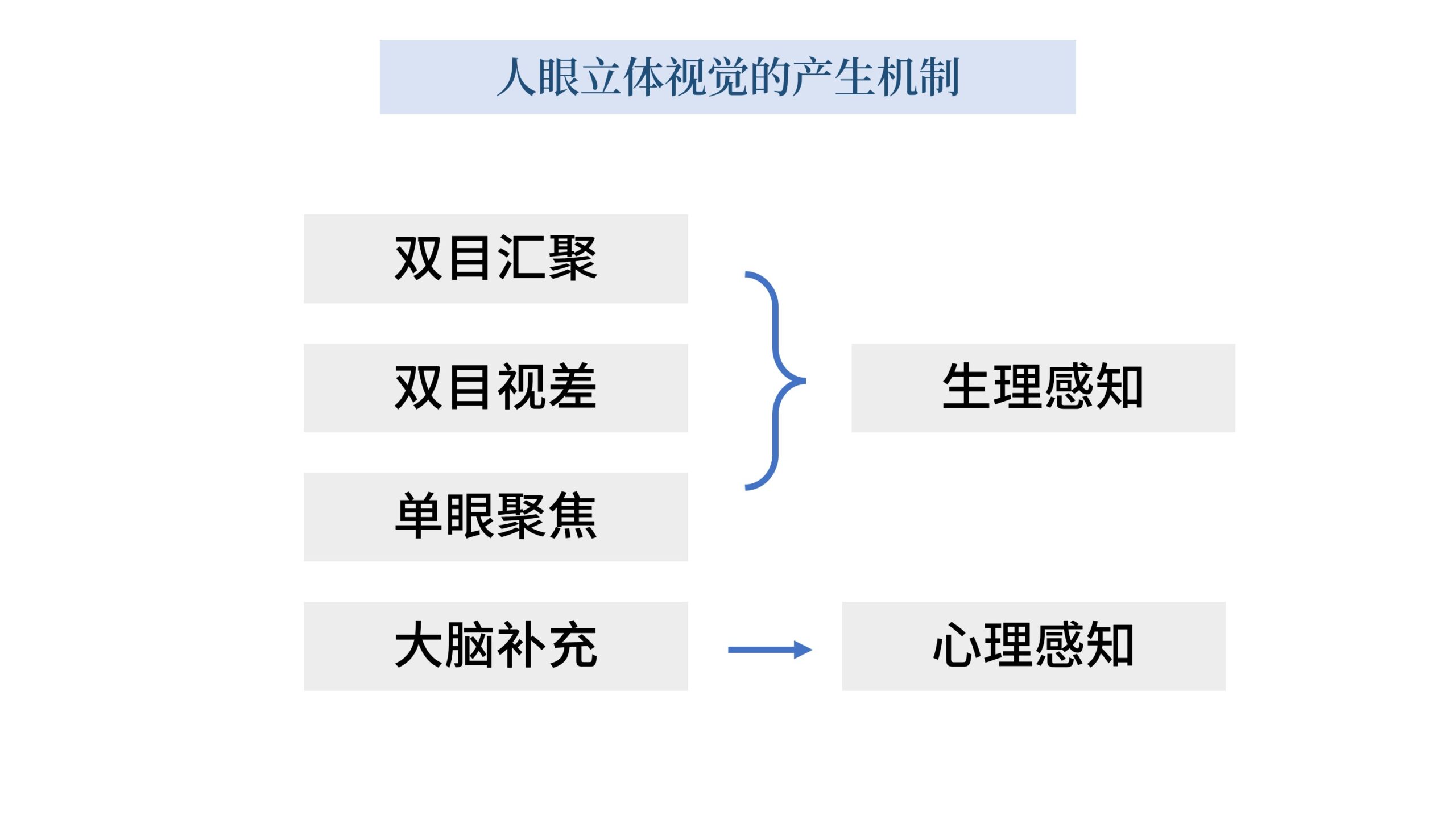
其中前3个属于生理感知,第4个属于心理感知。
这里我们先看「大脑补充」,简称「脑补」,它是一种心理感知。
我们在手机电脑等传统2D屏幕上看到的立体画面,其立体感基本上都来自于「大脑补充」。
手机、电脑上的这些2D画面本身并不携带深度信息,但是大脑会「脑补」这些2D画面的深度信息。
这种「脑补」可以大致上分为5类。
仿射、遮挡、光影、纹理、和经验。

首先是「仿射」。
这个概念其实比较难理解,它表述的是:
对于观察者而言,相对移动的物体的成像近似遵从「仿射变换」的规律。
为了不让这个视频变成数学课,这里我们暂时用「张角」的概念来简化「仿射」的部分。
等后续需要用到完整的「仿射」概念时再回过头来展开。
那什么是「张角」呢?
它的字面意思是「张开的角」,也就是物体所占人眼视野的视场角大小。
同一物体,离我们越近,其在人眼视野里的张角就越大,离得越远其张角就越小,也就是俗称的「近大远小」。
「张角」的概念非常重要,因为视场角是VR影像的基准坐标。
除了「张角」,其他四个则比较容易理解。
例如第二个「遮挡」,近处的物体会遮挡住远处的物体,符合我们的常识。
「光影」和「纹理」也可以让大脑感知到深度信息。
在3D游戏中,显卡渲染的重点其实就在于构建光影和纹理。
合理且精细的光影和纹理,能让画面拥有越好的立体感。
最后第五个是「经验」,如果一张图片里的鸽子和人一样大,那么说明鸽子距离人更近。
以上这五种都属于大脑自己补充深度的「心理感知」,它与用单眼或双眼无关,而是跟大脑有关。
无论是双眼还是单眼看到的画面,大脑都可以通过基于「张角、遮挡、光影、纹理、经验」自动脑补出深度信息。
因此这一机制可以在手机和电脑等传统2D屏幕上实现。
如果我们把人脑比作计算机,那么这类「心理感知」可以当作是纯软件的估算。
1.1 单眼聚焦
而事实上人类对于「深度信息」的获取,除了大脑的纯软件估算,还有一部分属于硬件测量,我们称为「生理感知」。
「双目汇聚」、「双目视差」、「单眼聚焦」就都属于这一类「生理感知」。
我们从比较简单的单眼线索说起。
人的单眼也有获取深度信息的机制,叫「单眼聚焦」Accommodation。
大家可以试着闭上一只眼睛,然后盯着自己眼前的手指,手指前后移动时,我们是可以察觉出距离的改变的。
这种单眼的距离感来源于,(1)人眼在聚焦时睫状肌的紧张状态,以及(2)焦外虚化的模糊程度。

在(1)里,单眼聚焦越近的物体,睫状肌会越紧张,聚焦越远的物体,睫状肌会越放松。
而在(2)里,我们的眼睛聚焦在手指上时,手指的画面就是清晰的。
但和手指位于不同深度的前后景处于焦平面之外,于是就都变得模糊了,并且离手指越远,就越模糊。
喜欢摄影的朋友应该了解这个原理,大光圈镜头追求「背景虚化」,最好是焦内如刀锋锐利,焦外如奶油般化开。
爆肝两个月 | 用动画的方式揭开光圈和景深的秘密——掌控曝光(—)
https://www.bilibili.com/video/BV1t24y1k7Ye
而人眼的成像方式也同样是凸透镜成像,我们可以把人眼可以看做是光圈值为F2.4-F6.8的相机镜头,所以它在对焦之后也会产生背景虚化。
于是,人眼可以依靠(1)单眼的睫状肌的紧张度,以及(2)单眼聚焦产生的前后景的焦外虚化程度,来一定程度上获取物体的深度信息。
这一机制就叫做「单眼聚焦」。
我们看视力表的时候要遮住一只眼睛,因为测视力的时候测的就是「单眼聚焦」的调节能力。
正常成年人在明亮的环境里,单眼聚焦的「调节能力」可以在0.2m到无穷远。
但如果光线变暗到0.01cd/m2,那么就只能调节从0.5m到2m的深度,也就是光线变暗时视力会下降。
但注意,这里说的是眼球晶状体的「调节能力」,而非单眼聚焦对深度的「感知能力」。
人眼基于睫状肌紧张和焦外虚化的深度「感知能力」,会远小于这个「调节能力」的数据。
「睫状肌」只有聚焦在近处时才会有明显的紧张感,而「背景虚化」还会受到瞳孔大小(光圈F值)改变的影响。
因此基于单眼聚焦的深度「感知能力」,是很容易受到干扰的,例如年龄增长,近视远视,环境光线的亮暗,甚至用眼疲劳也会有影响。
所以它并不精确,超过5m之后晶状体的调节就微乎其微。
而可能是因为我近视的原因,我自己体验觉得超过2米「单眼聚焦」就感知不明显,我会更依赖于用「大脑补充」去评估深度。
而现阶段在VR设备里,「单眼聚焦」这一条线索是失灵的。
卡马克有透露过,quest2的单眼成像焦平面为1.3米左右,我推测其他VR设备也大差不差。
1.3米这个设计还是有讲究的,一方面这个距离接近人站立和坐在椅子上时,看向地面的平均距离,1.3米是一个自然且熟悉的距离。
另一方面就是在传统的平面3D摄影中,有一些约定俗成的行业经验,例如一对3D摄像机的间距应该差不多要是到投影平面距离的1/20。
如果我们把双眼看做是一对3D摄像机,它的间距其实就是人眼的瞳距IPD。
瞳距按照平均65mm来算,乘以20得到的结果刚好就是1.3米。
当然我并不清楚VR厂商在做光学设计时,到底有考虑到哪些因素,以上这两个只是我自己的推测。
并且我也认为,部分传统平面3D摄影的经验其实并不适用于VR。
但无论如何,在目前VR设备里,人眼基于「单眼聚焦」获取的深度信息,它就只会是不变的1.3米,或其它某个固定距离,这取决于这个VR设备的光学设计。
但我们还是能够在VR设备里体验到丰富的立体感,而不会只觉得是在看距离为1.3米的2D大屏,这是为什么呢?
前面说了,在人眼对于深度信息的「生理感知」中,双眼线索的优先级要高于单眼线索。
而VR设备是一种双目显示器,它可以输出双眼线索的深度信息,这正是VR设备的奥秘所在。
VR设备的两只眼睛的显示一定是要分开的,而不能连在一起,哪怕只用了一块屏幕,中间也要用挡板给隔开。
我们想象一下有这样的一个VR眼镜,中间是连在一起的,是不 是视场角还能更大一点。
事实上还真的有这样的眼镜,一些穿越机的FPV图传视频眼镜就是这样设计的,因为它不需要3D显示,所以中间就直接连在一起。

而这样的屏幕是不能让双眼看到不同的画面的,无法对人眼输出基于双眼线索的深度信息,实际的观看效果就是一个2D大屏,沉浸感大打折扣。
我们在VR里也可以尝试体验这两者的区别。
你可以尝试在制作优良的3D全景视频里,把3D选项给关掉,调成2D模式。
此时播放器会把左眼(或者右眼)的一半画面复制相同的两份,共同输出到你的左右屏幕上。
那么这种模式下你就是在看一个距离为1.3米的2D大屏,它没有双目视差,丧失了能硬解的深度信息。
也就是在2D模式下,全景视频的立体感就只能靠观众自己软解「脑补」。
而如果只是「脑补」的话,它就跟手机电脑等单屏幕显示器没有区别了。
所以我一直强调,「深度信息」才是VR这种「双目显示器」最根本的特性,是「VR沉浸感」中最关键的事物。
1.2 深度信息而非自由度
那这部分再展开谈一个延伸话题,虽然放这里有点啰嗦,但我还是想聊聊。
很多人以为VR的特性是6自由度(6DOF),包括一大堆VR从业者也会有这样的误解,但其实不是的。
6DOF在手机和电脑上就能实现,大部分第一人称游戏就都是6DOF的。
实际上我也能理解为什么很多人会误以为VR的特性是6DOF。
因为在VR里我们能够获得到立体感,能感受到纵向的深度信息。
这种直观的立体感会本能地让人尝试从不同的角度去观察一个物体,例如走过去,换个角度看看侧面和背面是怎么样的。
而在传统的2D显示器上,你不可能绕到一个电视的后面,去观察画面中人物的背后。
因此很多人基于这种直观的体验,会将6DOF误解为是VR区别于传统屏幕的特性。
但实际上这种通过变换观看视角从而获得立体感的机制,有一个细分的称呼叫「移动视差」。
它是单眼就能感知的,可以被归类到「心理感知」中的「仿射」里。
因为变换视角去观察一个物体,就可以近似看成是物体的图像在做「仿射变换」。
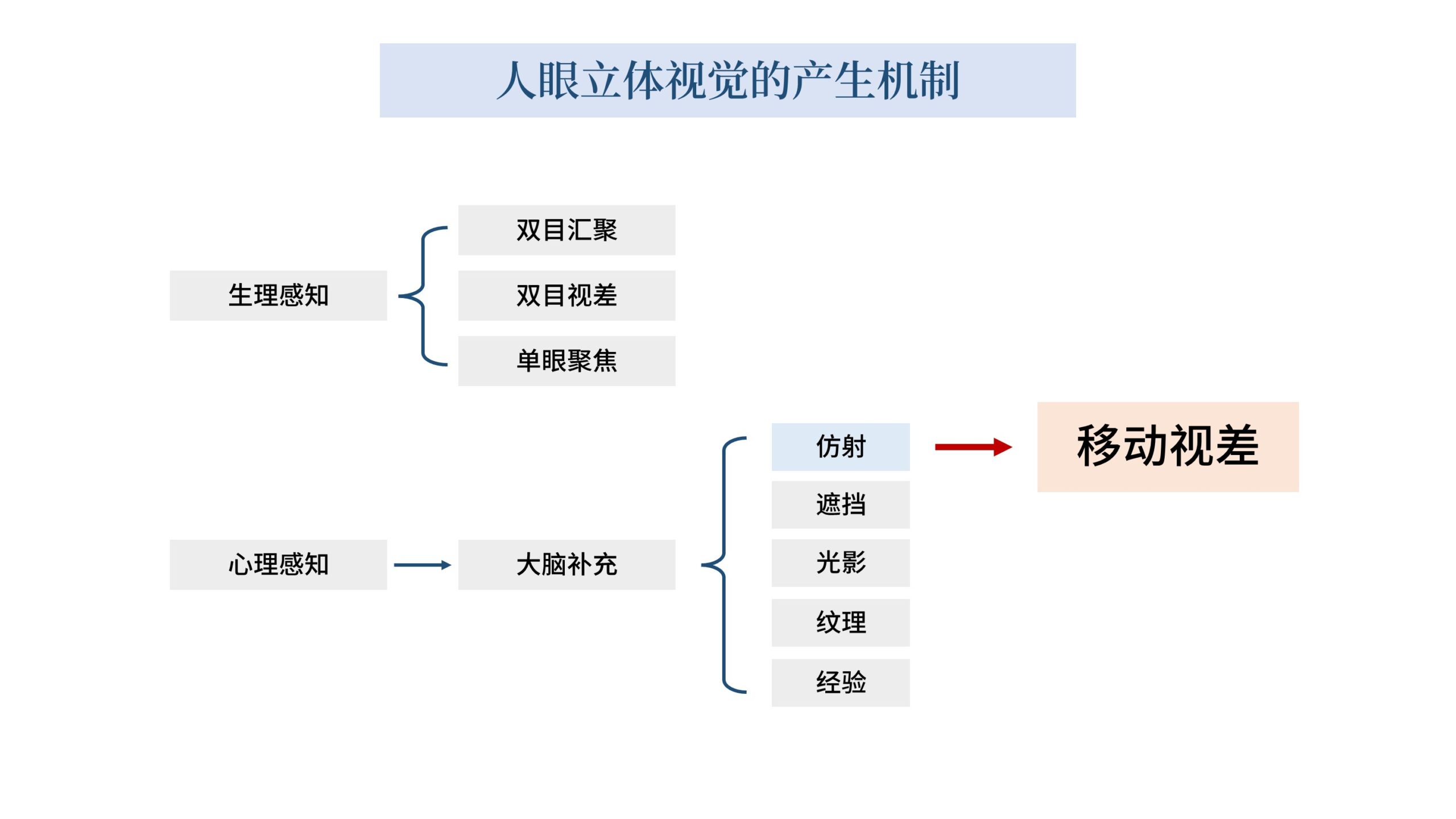
这种「移动视差」属于大脑补充,用单眼就可以感受到,因此它在2D的手机和电脑屏幕上也可以实现。
但是在VR里,获得立体感是不需要移动的,是在0DOF时就能达成的。
在VR里获得立体感不需要移动:
(1)不需要画面的移动
(2)不需要观看者的移动
因为VR是一种双目显示器,可以输出基于双眼线索的不同画面。
而人的双眼可以对两幅画面进行直接的硬件解码,从而获得深度信息,这是一种直接的生理感知,你不需要移动自己的位置。
因此VR独占的特性是深度信息,而不是6DOF。
如果某个VR应用的核心特性是6DOF,那么它就没有核心特性,因为在电脑和手机也能实现6DOF。
那说得有点多了,现在我们回到讨论的话题主线。
人脑基于双眼线索的深度感知,又可以分成2个部分,「双目汇聚」与「双目视差」。
这一过程是自动发生的,并且涉及到一些主观的心理活动,因此要解释这一机制,就有点像要去解释我是如何骑自行车,或者我是如何游泳的一样,是一件麻烦的事情。
不过,跟着我的思路来逐一梳理,应该还是可以去理解这一机制的。
我们开始这一期视频的正片。
2. 双目汇聚的定点测距
人眼的结构还是挺复杂的。
不过它的基本原理仍然是我们中学物理课上学的凸透镜成像,光线透过眼球在视网膜上成倒立缩小的实像。
视网膜上成的像,实际是中间清晰、四周模糊的。

视野中心的一小块区域我们称为「注视点」,它在视网膜上的对应成像区域称为「中央凹」。
「中央凹」是视网膜上视锥细胞最密集的区域,因此在此处成的像分辨率最高,最清晰。
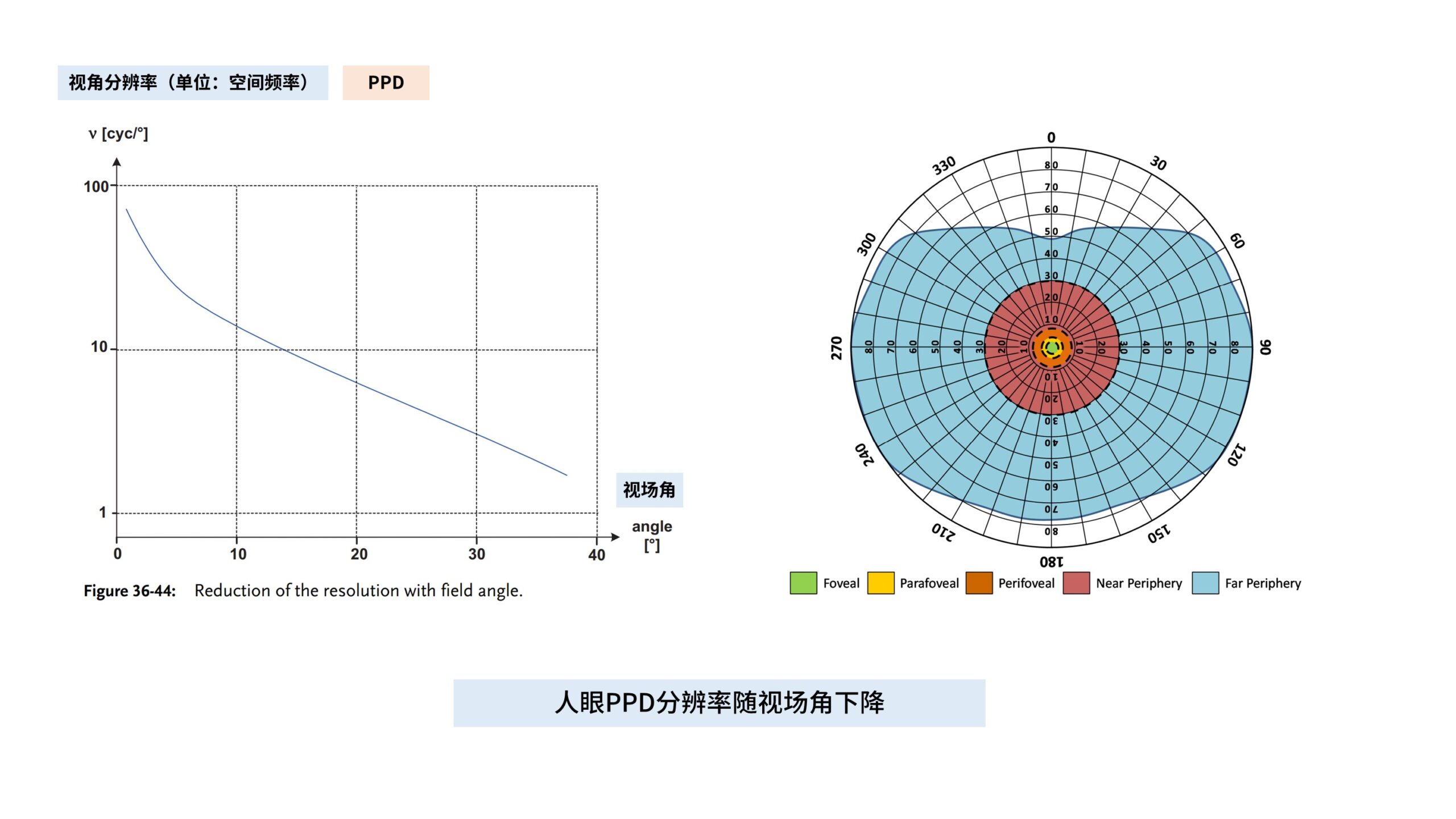
如图所示,横轴是人眼视网膜的视场角偏离「中央凹」的角度。
纵轴则是空间频率,cycles per degree (cyc/°),这里可以把空间频率近似理解成人眼的PPD分辨率。
注意这里的纵轴坐标是非线性的。
在中心区域,单眼的视力是超过60PPD的,而一旦偏离中心15°,视力会下降到10PPD以下。
不过「中央凹」的位置其实并没有完美地位于视网膜的中心点。
实际上「中央凹」往太阳穴侧偏移,对应的「盲点」则会向鼻侧偏移。
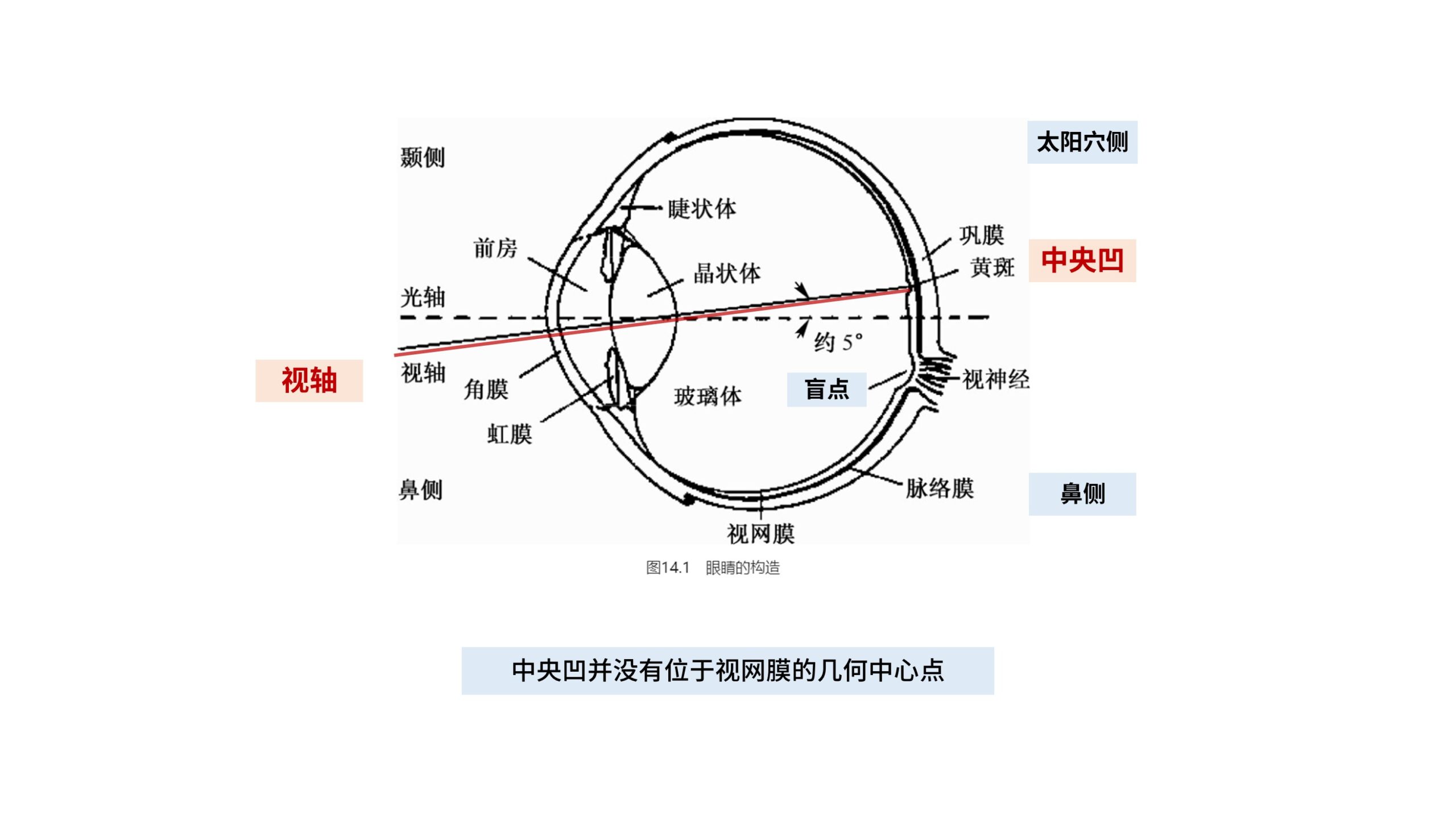
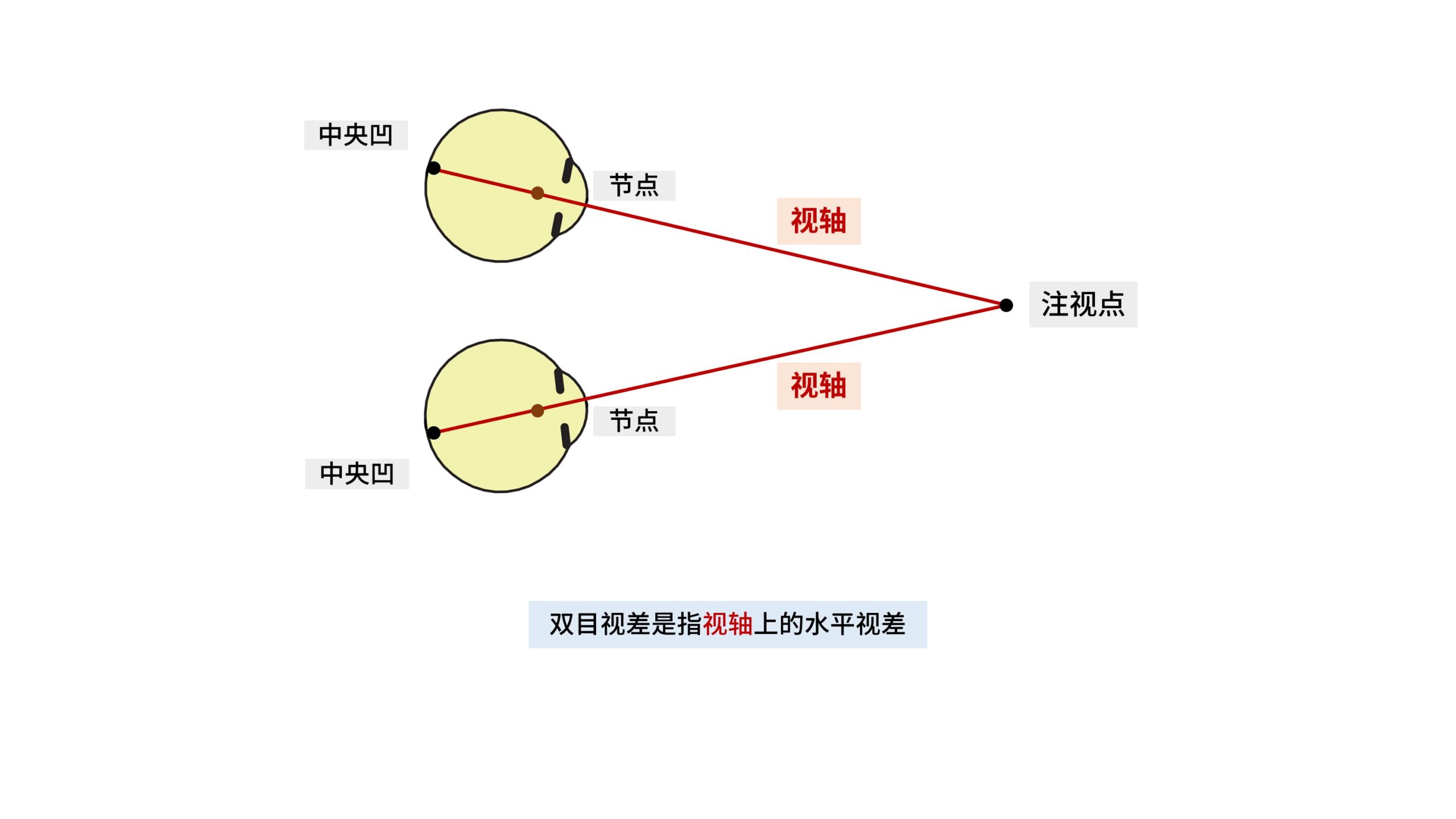
我们在讨论「双目汇聚」时,汇聚的主体是「视轴」。
而「光轴」则是眼球几何上的中心轴,「视轴」和「光轴」的夹角大概为5°。
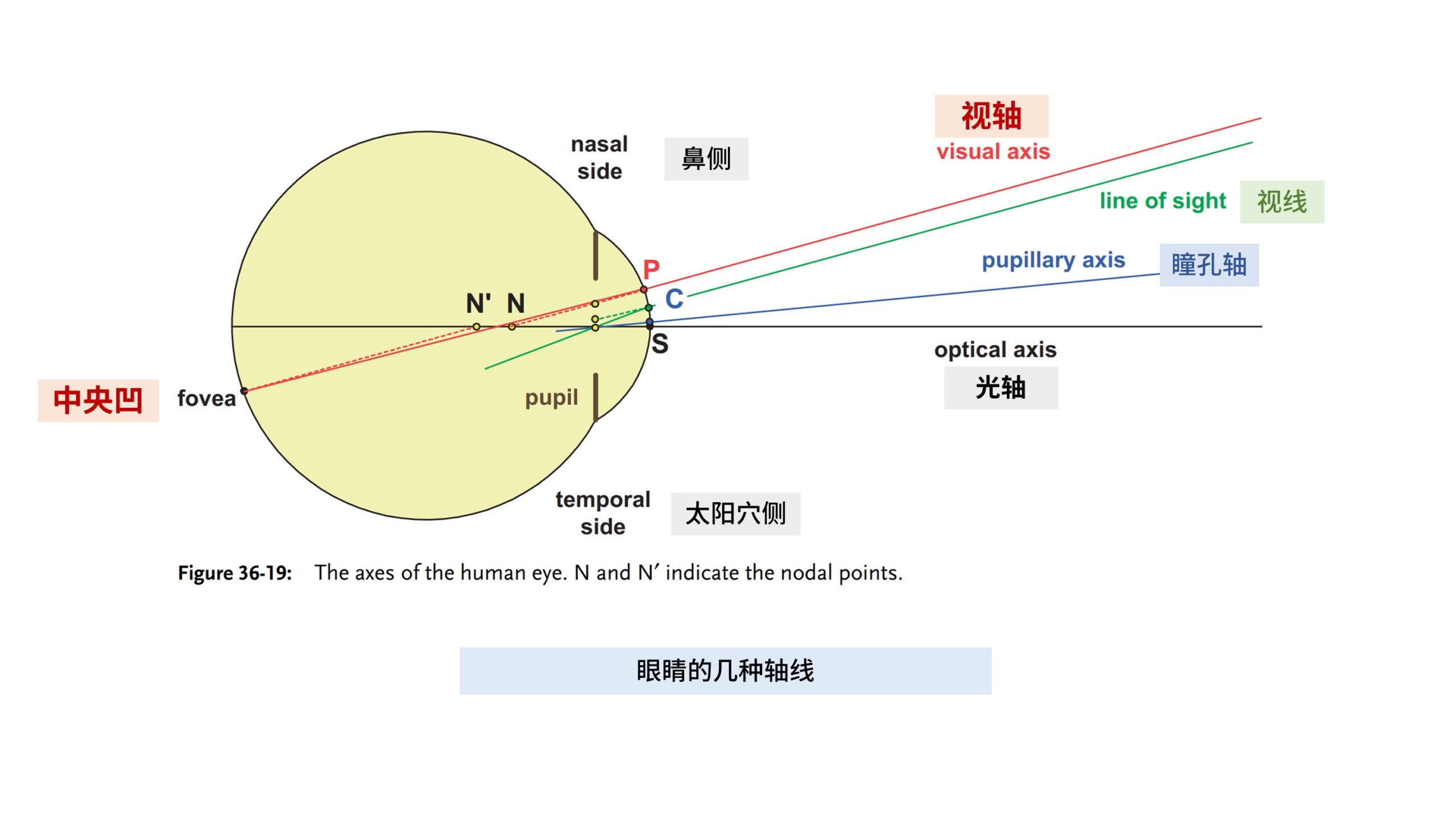
左右眼两条「视轴」交汇的点就是我们的「注视点」。
或者反过来说,过「注视点-节点-中央凹」的轴线就是我们的视轴。
在视网膜上,只有沿着视轴落在「中央凹」区域的一小块的视野是清晰的,而其他区域是模糊的。
当你想看清视野中的某处时,大脑会转动眼球,调整视轴,把注视点切换到你关注的区域,始终保持你的「注视点」沿着「视轴」落在视网膜的「中央凹」上。
因此我们会产生视野里看到的所有东西都是清晰的的错觉, 实际上只有注视点的那一小块区域是清晰的。
VR里的「注视点渲染」「注视点投影」等技术,其实就是利用了人眼的这一特性。
人的左右双眼的两条视轴,会交汇到视野中的某个点上,这一过程就叫「双目汇聚」
很多地方会将「Vergence」翻译成「辐辏」。
我认为这个翻译非常差,所以拒绝使用它,在我的频道里我都会把「Vergence」称为「双目汇聚」。
「双目汇聚」具有定点测距的功能。
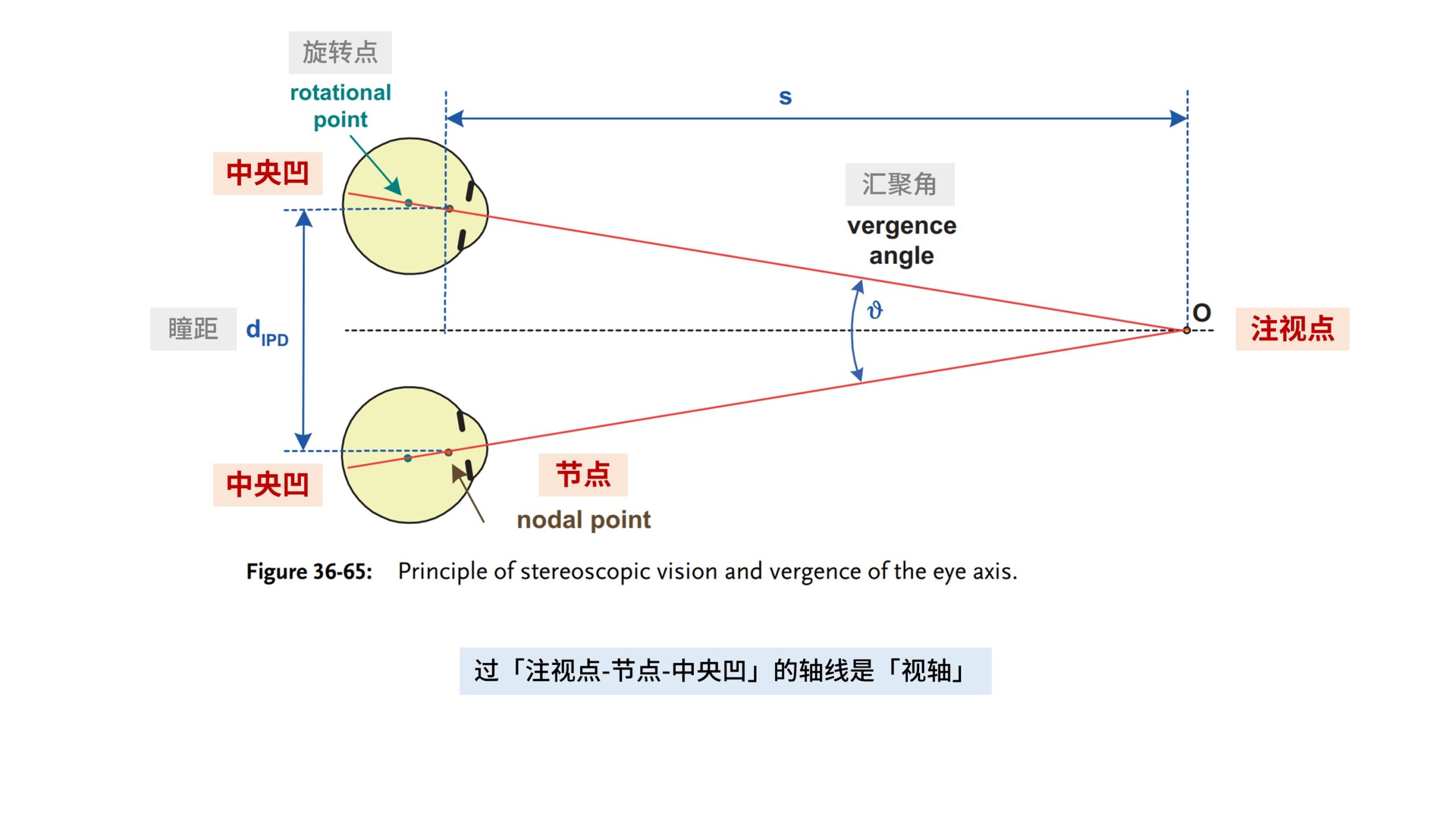
当我们左右眼注视在同一个位置时,两条视轴交汇在一点,形成一个夹角,这个夹角就叫做「汇聚角」。
我们暂时先只考虑正前方位置,当「注视点」处于不同的深度时,汇聚角会有所不同。
当注视点越近时,汇聚角越大,当注视点越远时,汇聚角则越小。
「汇聚角」由两只眼睛转动的角度决定,而眼球转动时眼部肌肉的紧张情况,我们是有直接的生理感知的,所以它是一种「硬件测量」。
汇聚越近的物体,眼部肌肉会紧绷,过于斗鸡眼时甚至会觉得难受。
而在看向无穷远处时,两条视轴近似是平行的,此时眼部肌肉是最放松的。
因此这种眼球转动一定角度带来的细微肌肉紧张变化,能够让人类判断注视点离我们的距离,从而获取注视点的深度信息。
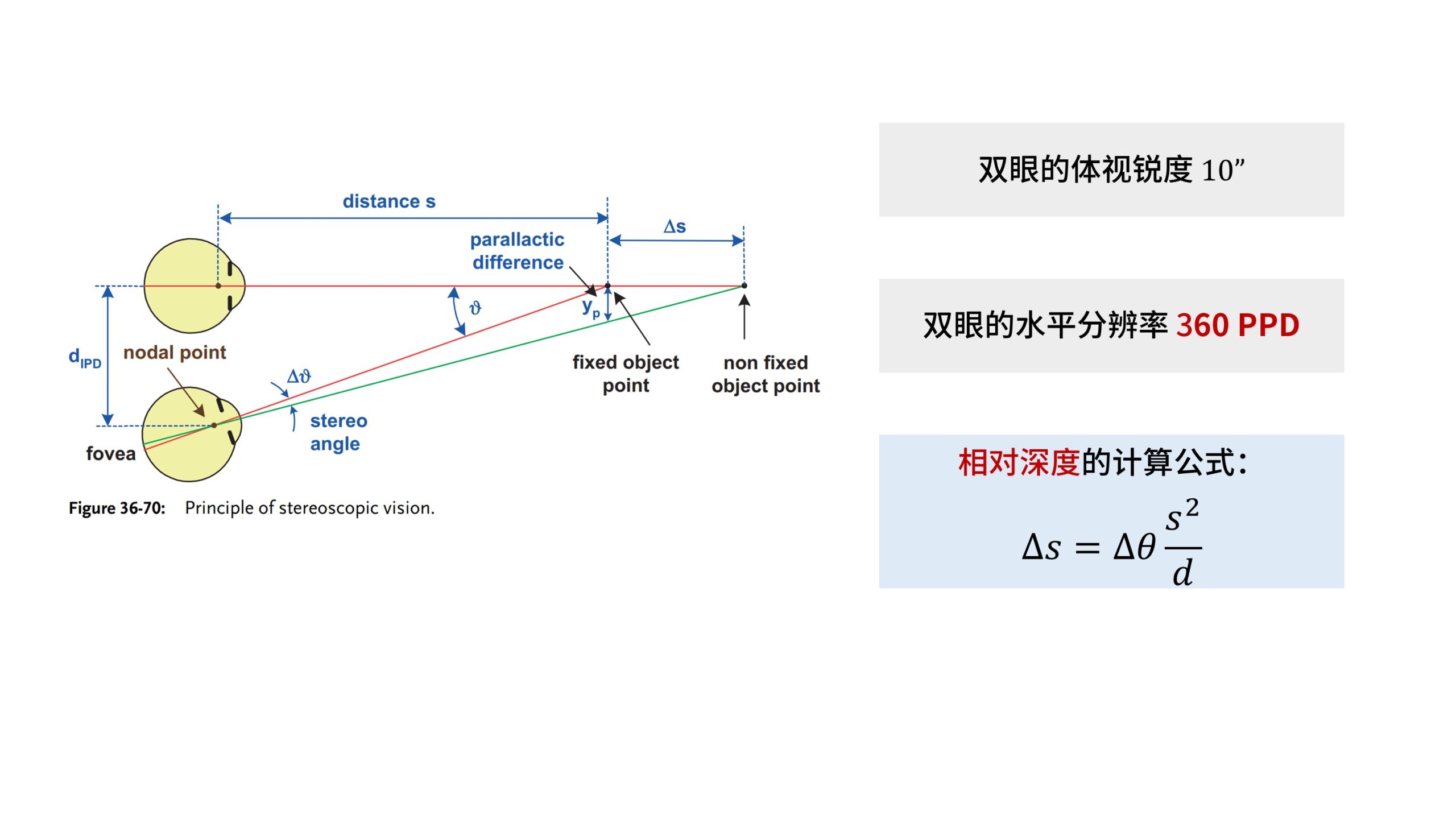
假设双眼的瞳距为d,汇聚角为θ,深度为s。
因为s远大于d,我们可以把d近似看做是半径为s的圆上的一段弧
于是可以简单地列出深度信息的计算公式:s = d/θ
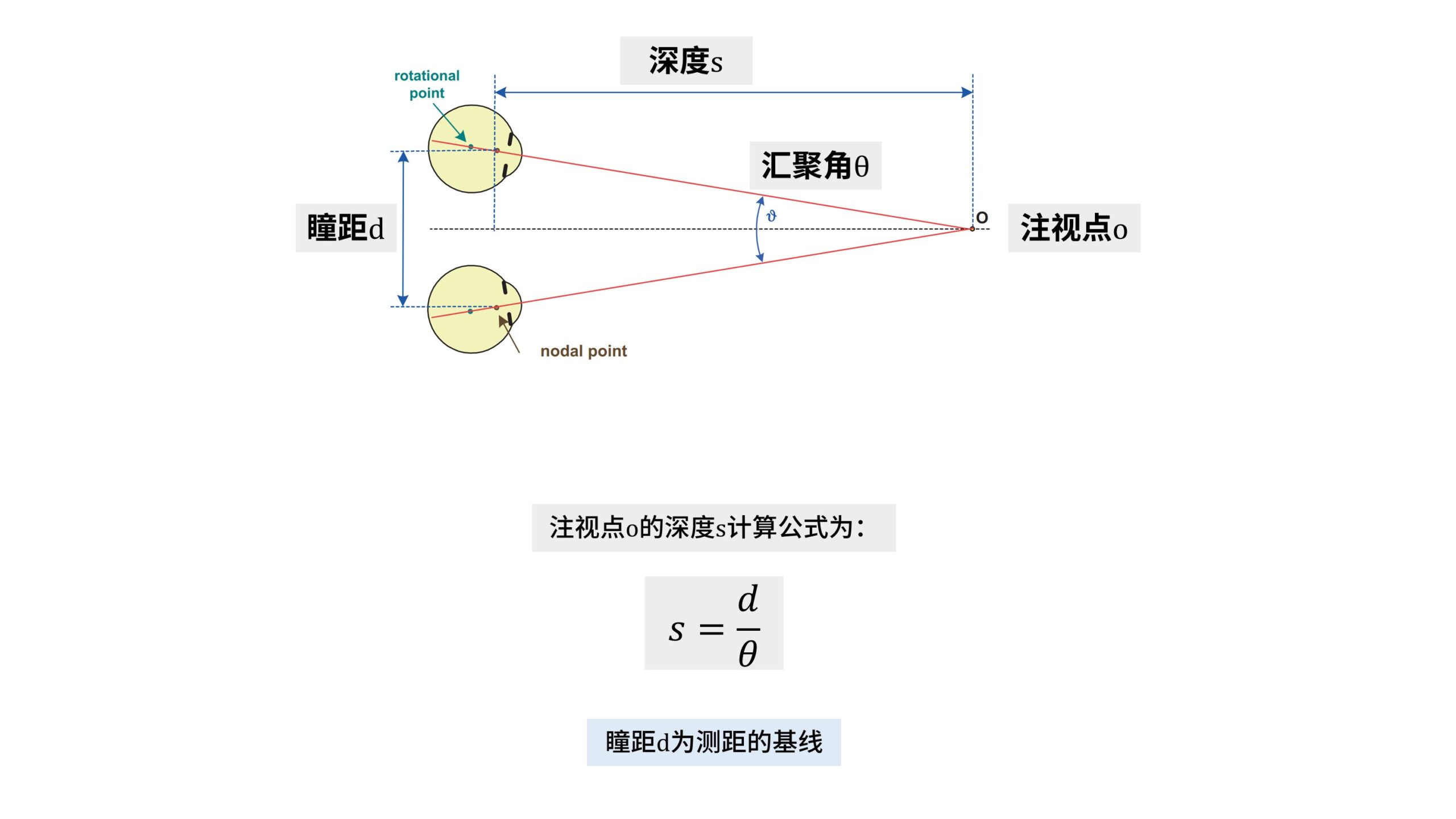
这里的是弧度制的,单位为rad
1 rad=180°/π≈57°
其实这就是一个定点测距的过程,瞳距d被称为测距的「基线」。
也就是说,人类以自己的瞳距作为尺度基准,通过感受因不同「汇聚角」所产生的肌肉紧张程度,从而得到注视点的深度信息。
这一种获取「深度信息」的机制就叫「双目汇聚」。
当然实际上我们的大脑并没有这样的一个精密的计算过程。
大脑基于「双目汇聚」的深度感知是一种肌肉记忆,它是一个主观的感受,就像我们用手去感知一杯水的温度,也是一种大概的估计,而不是精确到具体的水温 55℃。
因此「双目汇聚」感知注视点的深度信息的绝对精度是不高的,我们只能大致判断眼前这个物体离自己的距离,并不能说精确到多少厘米。
在近距离下这种估计还是比较准的,但是超过16m之后,视轴基本上是平行的,单靠「双目汇聚」无法得出准确的深度信息。
所以「双目汇聚」常常会配合其它机制一起进行深度估计,包括「单眼聚焦」和「大脑补充」,从而得出我们的注视点的大致深度。
2.1 VAC问题
那到这里,其实我们已经介绍了单眼聚焦Accommodation和双目汇聚Vergence。
那么顺便也提一下之前提到过的VAC问题,也就是
Vergence–Accommodation Conflicts
一般直译为「辐辏调节冲突」,「辐辏」是Vergence,「调节」是Accommodation。
那我前面也说了,这样的翻译是非常差劲的,在制造不必要的理解门槛。
那在我的这个频道里,Vergence翻译为「双目汇聚」,Accommodation翻译为「单眼聚焦」。
即「VAC问题」可以直译为「双目汇聚/单眼聚焦-冲突」
那这里我将其意译为「聚焦深度不同步」。
造成VAC冲突的原因在于,在深度感知中,「双目汇聚」和「单眼聚焦」常常是联动的,两者互相配合以更准确地判断深度。
双目汇聚到近处时,单眼聚焦的也常常对焦在近处。
我们可以看这张图,横轴是「双目汇聚」的程度,单位是棱镜度;纵轴是「单眼聚焦」的程度,单位是屈光度;最左边还有一条纵轴则是对应的是深度。
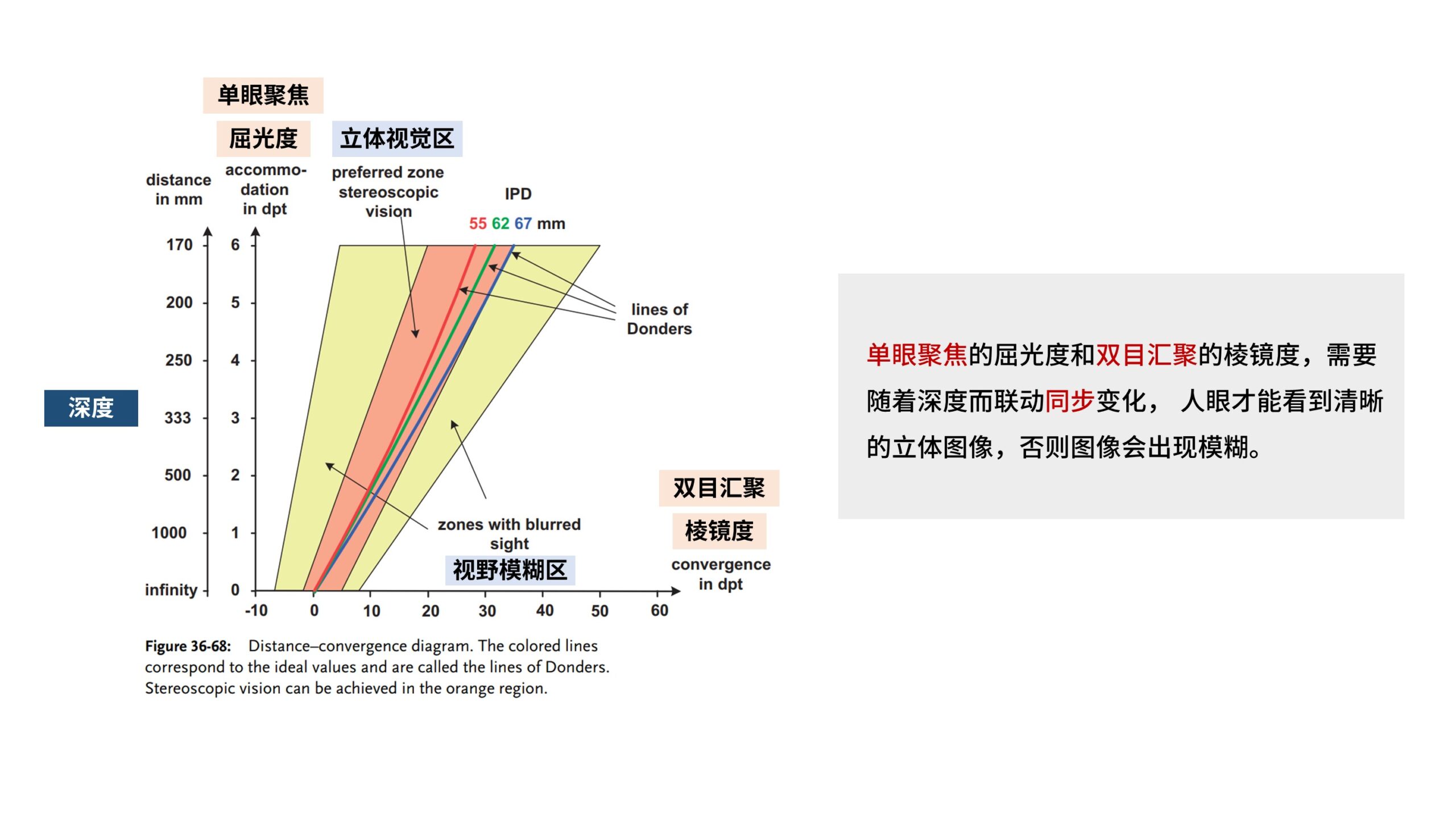
这张图说明了,单眼聚焦的屈光度和双目汇聚的棱镜度,需要随着深度而联动同步变化, 人眼才能看到清晰的3D图像,否则图像会出现模糊。
直观地来说,转动眼球的眼部肌肉,和控制晶状体收缩的睫状肌,这两种肌肉常常会同步工作,一起紧张,一起放松,同步到相同的深度,才能看到清晰的立体图像。
在现实里,假设「双目汇聚」的注视点在近处的0.2米,那么我们会有点斗鸡眼,转动眼球的眼部肌肉会感到很强的收缩压力。
此时「单眼聚焦」的睫状肌也会自动同步收缩,控制晶状体的曲率变大焦距缩短,让「单眼聚焦」也同步对焦到0.2米处。
但是在VR里,显示屏幕的焦平面永远是固定的1.3米(以quest2为例)。
当双目汇聚到0.2米处时,「单眼聚焦」也对焦到了近处的0.2米,那么1.3米的屏幕就在焦平面之外,会产生背景虚化,变得模糊。
于是眼睛就会看到类似近视一样的画面模糊。
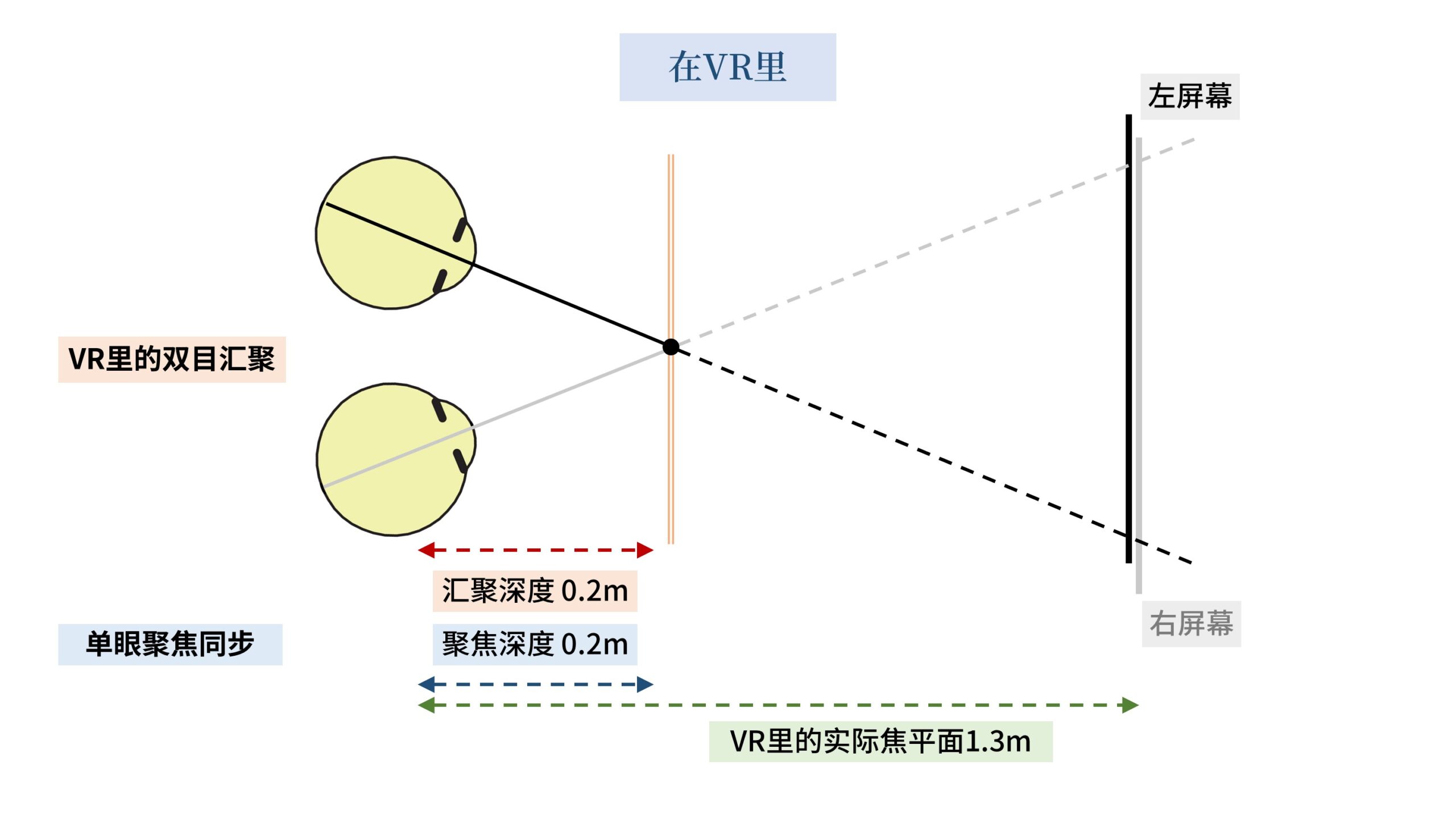
注意,此时人的双眼汇聚到0.2米处,单眼因为眼部肌肉的联动也聚焦到了0.2米处。
人体在这里是没有出错的,眼部肌肉和睫状肌同步调整到0.2米的深度。
但是VR光学透镜的焦距一直是固定的1.3米,并没有同步变换到0.2米处。
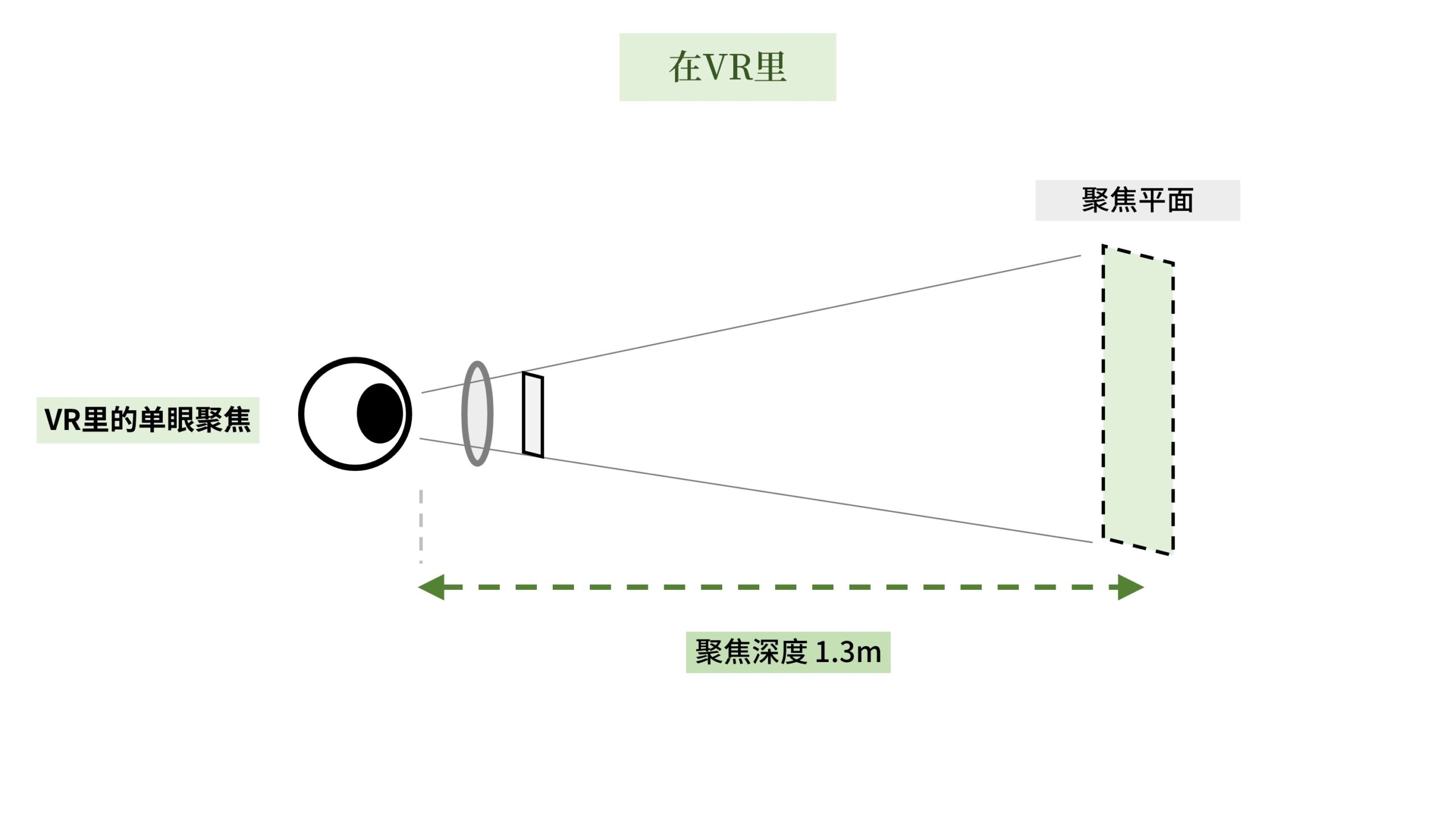
因此出错的是,VR眼镜的光学透镜的焦距,没有随着双目汇聚而同步。
所以我将VAC问题意译为「聚焦深度不同步」。
要解决VAC问题,VR光学透镜要具有可变的焦距。
并且需要配合「眼动追踪」,通过计算人眼的双目汇聚角,以反推「汇聚深度」,再改变光学透镜的「聚焦深度」与之同步。
那在当下,我也听到很多人说现在的「注视点渲染」可以解决VAC问题。
这一说法其实是有问题的。
我们在第【1】小节里说过,通过「单眼聚焦」获取「深度信息」有两种途径:
(1)单眼的睫状肌的紧张度
(2)单眼对焦后,前后景的虚化程度
「注视点渲染」只能模拟焦平面之外的前后景虚化,但无法改变人眼睫状肌的紧张度。
也就是说,「注视点渲染」可以解决「单眼聚焦」的(2),但无法解决(1)。
并且它解决(2)的方式是靠软件模拟。
但是,用软件模拟解决(2)的前提是,先用硬件解决(1)。

软件能让液晶屏幕上已经对上焦的清晰图像变模糊,但没有办法让人眼视网膜上对不上焦的模糊图像变清晰。
因此,在可变焦透镜的技术成熟之前,单独的「注视点渲染」是没有办法解决VAC问题的,路还很漫长。
所以现阶段在VR里,你看远处的东西是清楚的。
而看凑得非常近的东西时,反而觉得很模糊,自己像是近视了一样。
注意是整个视野全部模糊了,因为全部都没对上焦。
但此时你只要闭上一只眼睛,屏蔽掉「双目汇聚」的机制。
「单眼聚焦」重新聚焦到1.3米的正确焦平面处,那么模糊的画面就会恢复清晰。
此时如果再次从单眼切换到双眼,高优先级的「双目汇聚」深度的又会覆盖掉「单眼聚焦」,让整个画面变得模糊。
这种体验非常有趣,大家可以自己在VR里试试。
3. 双目视差的定面测距
单独看每只眼睛,其成像原理都是凸透镜成像,光线通过眼球透镜在视网膜成倒立缩小的实像。
视网膜上的这个实像是2D的,它和相机传感器拍照的原理没有什么太大不同。
也就是说即使在现实里,人每只眼睛看到的原始画面也都是2D的,3D的立体视觉是大脑后期处理的结果。
那前面所提到的「双目汇聚」就是一种立体视觉的生理感知。
运用「双目汇聚」人眼可以进行定点测距,我们可以通过「汇聚角」去感知「注视点」的深度信息。
但「双目汇聚」这一机制实际上只测了注视点区域的深度,而我们的立体视觉其实并非只局限于一个小点,而是整个视野都是3D立体的。
那么人眼和大脑究竟是如何把平面的2D图像,给解算成3D的立体空间的呢?
这就需要依靠「双目视差」。
那接下来的这些关于「双目视差」的解释,有许多是我自己独自思考并整理出来的结论,不一定对。
因为立体视觉太过主观了,有很多机制是自动发生的,分析这些机制需要你去解析自己的心理过程。
所谓的「视差」大致上可以理解为光轴的位置移动之后,成像发生了改变。
对于人眼,这条光轴准确来说是指过「注视点-节点-中央凹」的「视轴」。
左右眼的两条视轴在空间上并不重合,因此两只眼睛看到的画面是有差异的。
并且因为双眼是水平左右排列的,因此这个「视差」属于「水平视差」。
回想一下,「双目汇聚」在汇聚视轴的时候,左右眼的视轴会交叉在一个点上。
假设这个点足够小,那么对于左右眼来说,这个注视点就是没有视差的。
事实上此时不仅仅是这个点是没有视差的。
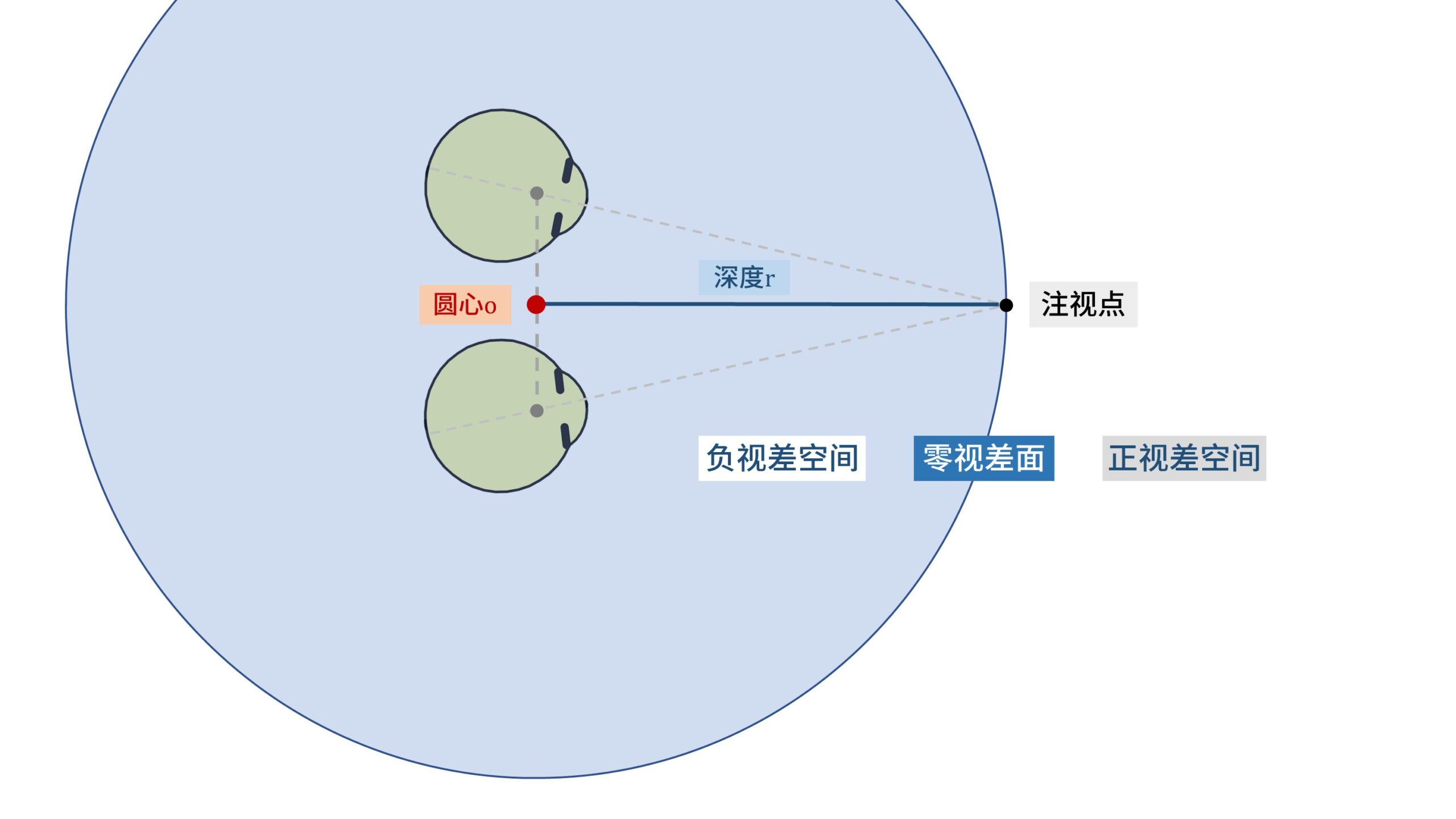
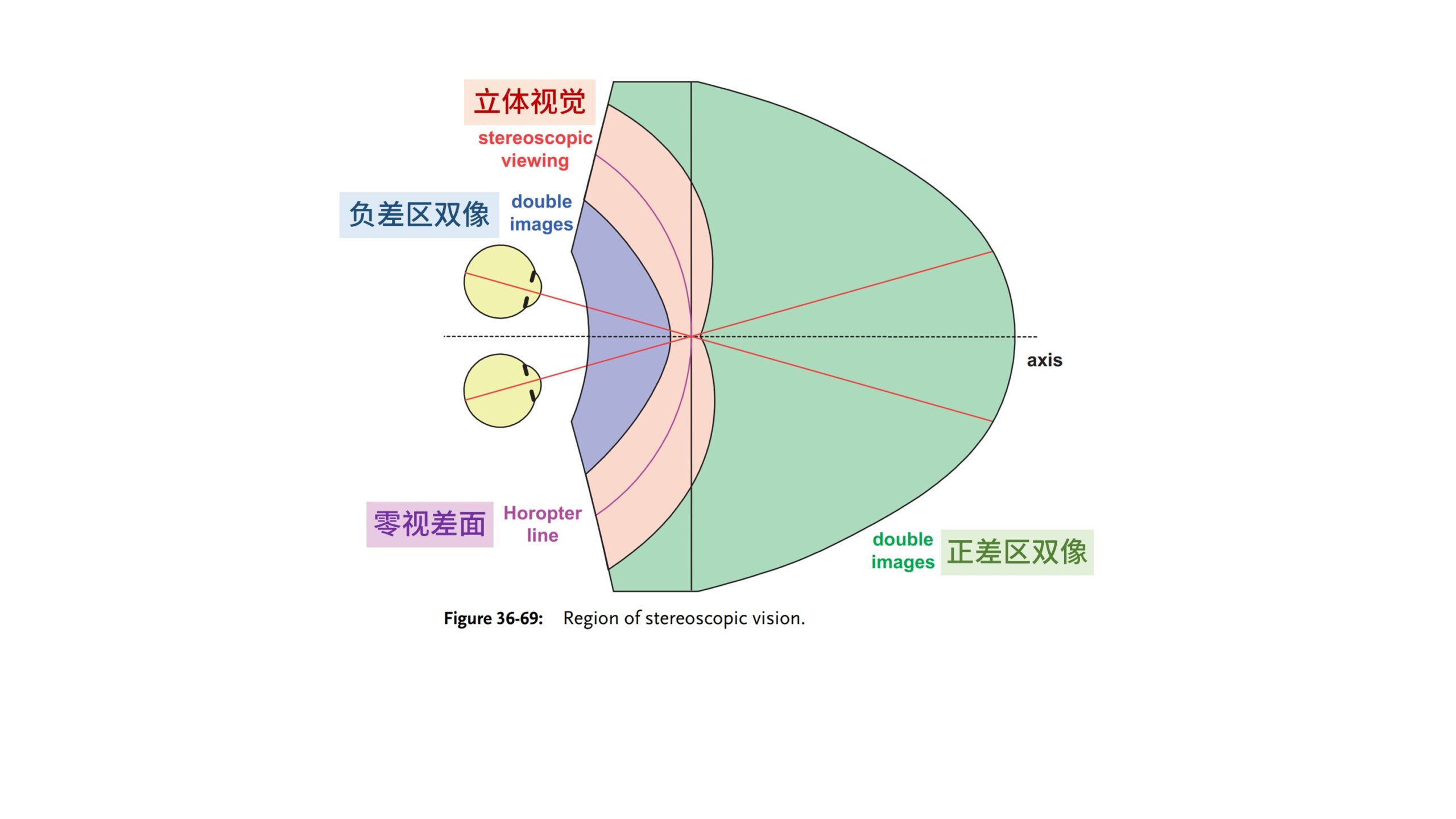
我们用这个「注视点」的深度为半径,以瞳距的中点为圆心画圆,那么就能得到一个没有视差的球面,称为「零视差面」。
位于「零视差面」的物体在左右眼睛视网膜上成的像,大脑能够将其融合成一个「单像」,形成立体图案。
以「零视差面」为0点,靠近人眼的区域称为「负视差空间」,远离的区域称为「正视差空间」。
在正负视差空间里,物体在左右眼睛成的像无法融合成单一的图案,会成「双像」。
那听我这样干讲并不直观,屏幕前的你可以跟着我的描述一起来操作。
我们可以试着将两只手指放在正前方,A近B远,大概在距离人眼20cm和40cm的位置。
【此段建议在B站上看视频的动态演示】
VR沉浸感的奥秘,人眼如何通过双目视差硬解深度信息【双目VR摄影#V1】
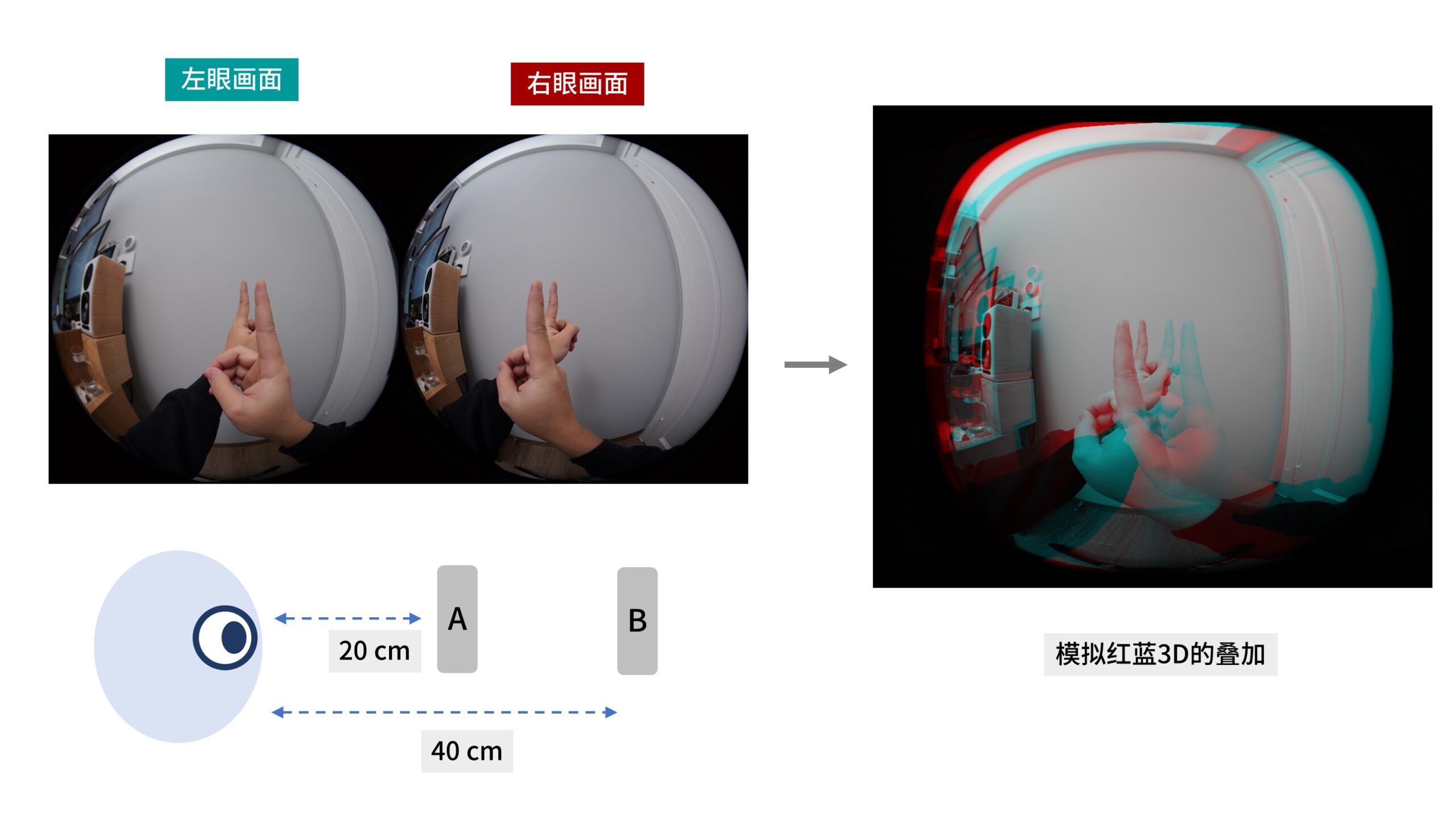
这里为了方便演示,我用双目相机拍了一张立体照片,近处的右手指为A,远处的左手指为B。
然后模拟红蓝3D的形式对照片进行处理。
即左眼只看到青色画面,右眼只看到红色画面,左右眼叠加后形成立体图像。
屏幕前的你请看向自己的手指,听着我的描述,对照着视频一起操作。
请用眼睛的注视点盯着自己近处的手指A,并同时用余光留意远处的手指B。
此时我们就能够感觉近处的手指A成「单像」,而远处的手指B成「分散」的双像。
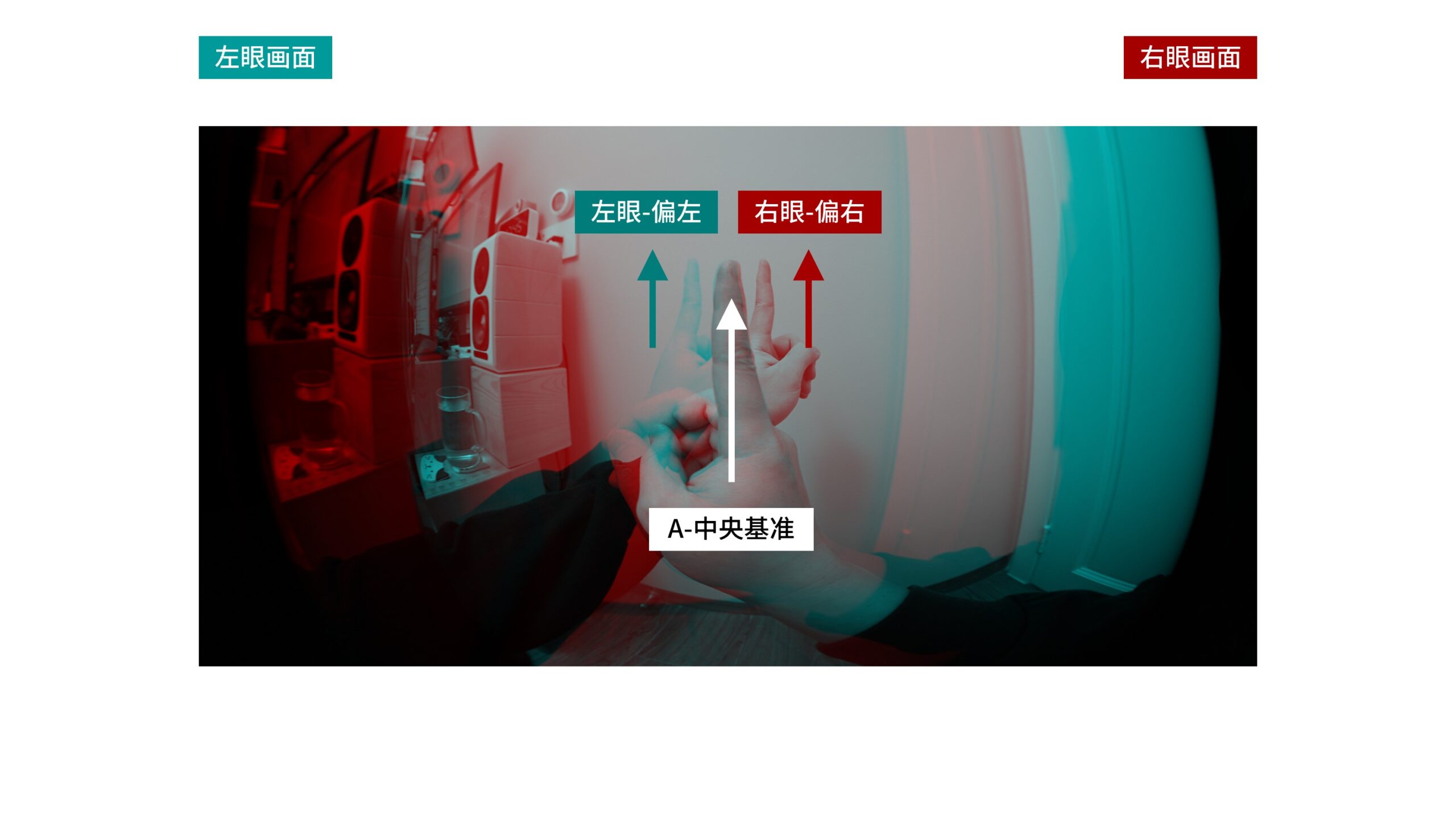
「分散」的意思是,以「零视差面」上的手指A的单像为中央基准,在左眼看来手指B偏左,而在右眼看来手指B偏右。
也就是说,此时手指B位于「正视差空间」,其双像都是「分散」的,具有「正视差」。
然后同样保持这样A近B远的两只手指的位置。
此时我们把注视点从近处的A,重新汇聚到远处的手指B上,注意感受眼球的转动和眼部肌肉的紧张变化。
当注视点汇聚到远处的手指B时,手指B先前「分散」的双像会融合成一个「单像」,手指B所处的球面成为新的「零视差面」。
此时我们的余光留意近处的手指A,能够感觉手指A成「交错」的双像。
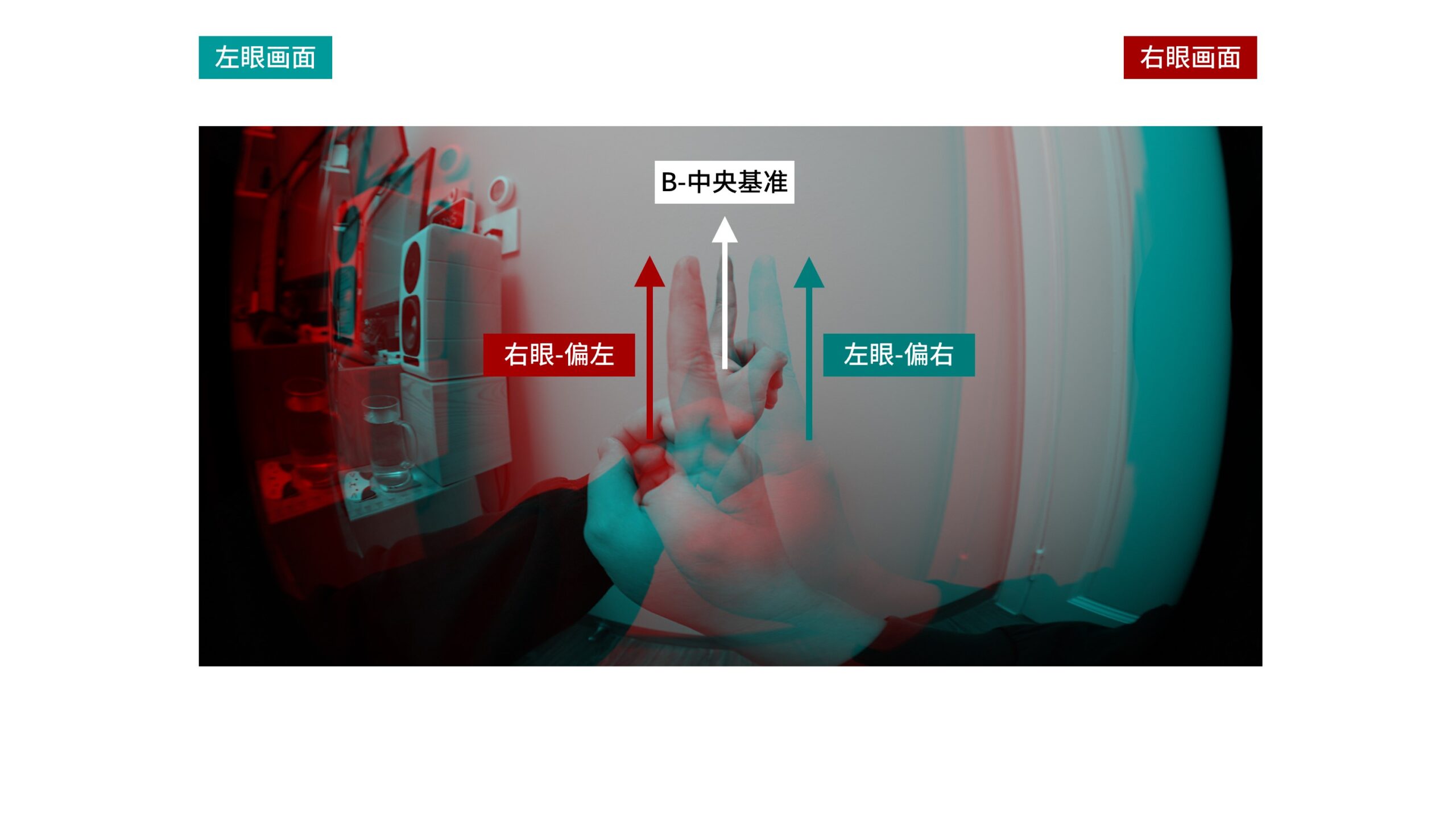
「交错」的意思是,以「零视差面」上的手指B的单像为中央基准,在左眼看来手指A偏右,而在右眼看来手指A偏左。
也就是说,手指A位于「负视差空间」,其双像是「交错」的,具有「负视差」。
那到这里我们先暂停一下。
为了方便后续所有视频的讨论,这里我们有必要先约定一些用语,并做适当的简化。

「双目汇聚」时,以「视轴」交汇的「注视点」的深度为半径构成的球面,称为「零视差面」,我们简称为「零差面」,这里的视差均指「水平视差」。
以「零差面」为分界, 深度大于「零差面」半径的空间叫「正视差空间」,简称「正差区」。
深度小于「零差面」半径的空间叫「负视差空间」,简称「负差区」。
在「零差面」上的像没有视差,或称为有「零差」,双眼可以融合成一个「单像」。
位于「正差区」的像有「正差」,双眼成「分散的双像」,简称「散像」。
位于「负差区」的像有「负差」,双眼成「交错的双像」,简称「错像」。
「分散」是指以「零差面」为中央基准,左眼看到的像偏左,右眼看到的像偏右。
「交错」是指以「零差面」为中央基准,左眼看到的像偏右,右眼看到的像偏左。
双像的深度越偏离「零差面」,其「分散」或「交错」的程度就越大。
「零差面」通过「双目汇聚」来确定,这一过程描述为「对齐视差」,简称「对差」。
「对差」确定「零差面」,并划分「正差区」和「负差区」。
至此,我们终于可以给「双目视差」做一个严格的定义。

人眼通过双目汇聚进行「对差」,然后划定以瞳距中心为圆心、以注视点深度为半径的「零差面」。
深度等于「零差面」半径的图案成单像,深度远离「零差面」的图案会成双像。
大脑通过分析所有双像「分散」或「交错」的程度,以确定各个双像与「零差面」的「相对深度」。
最终在脑海中呈现出一整个完整的立体视野。
这种获取深度信息的立体视觉机制,就叫做「双目视差」。
「双目视差」并非是大脑的纯软件计算,它是有硬件基础的。
人眼在「对差」的时候,注视点沿着「视轴」落在「中央凹」上,这是视网膜上分辨率最高的地方。
我们前面提到过,视网膜中央凹处的分辨率是60PPD,但这其实指的是单眼的分辨率。
其对应着单眼60”的视角分辨率,60”也就是1’或者1/60°
而一旦启用双眼,那么因为双眼距离为瞳距,两条视轴的角度有所不同,于是不同深度的注视点落在左右眼视网膜上的图像会偏离一个微小的角度。
这个角度最小可以到10”,称为人眼的「体视锐度」。
换句话说,当启用双眼之后,人眼在水平方向上的分辨率可以达到360PPD。
而双眼的这个超高的水平分辨率,其实是用来高精度地计算「相对深度」的。
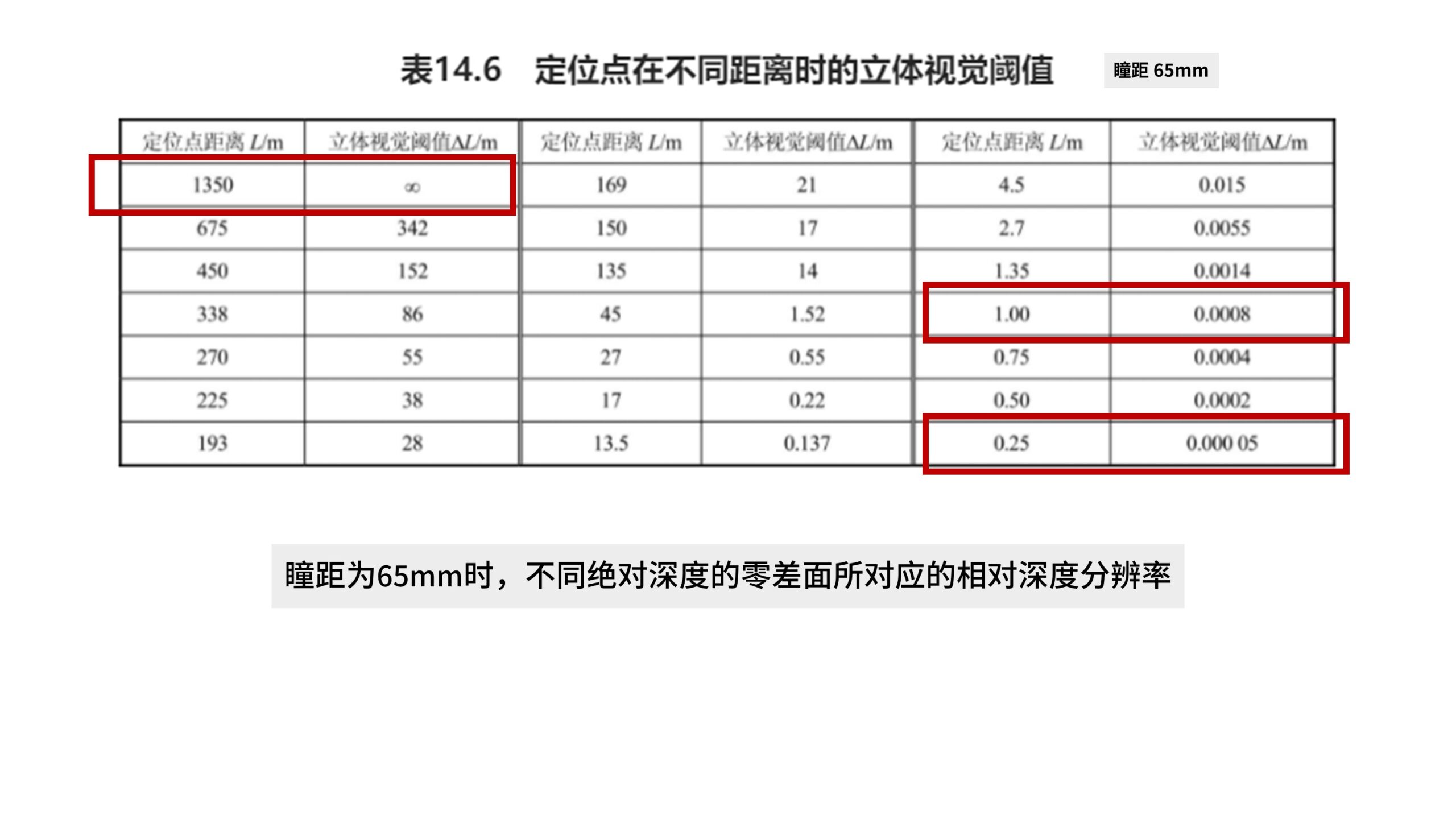
我们按照65mm的瞳距来计算。
当「零差面」的绝对深度为1m时,「双目视差」能感知的相对深度的分辨率为0.8mm。
也就是离我们1m和1.0008m远的两个靠得很近但处于不同深度的点,人眼依靠「双目视差」是分辨得出来前后关系的。
「零差面」越近,相对深度的分辨率就越高,在25cm处,相对深度的分辨率为0.05mm。
而最远的「零差面」是1350m,超过这一距离后,人眼就无法再用「双目视差」分辨出相对深度。
也就是如果只基于「双目视差」,1350m远的物体和无穷远的物体看上去就好像是在同一深度上。
那1350m是按照360 PPD算的,如果按照目前VR设备的20 PPD算,这个距离就是75m。
也就是在20 PPD的VR眼镜里,「双目视差」的测距极限是75m,超过75m的图像像素在左右屏幕上没有水平视差。
3.1 硬解的深度信息
到这里我们回顾一下,人眼立体视觉的产生,有多种机制。
双目汇聚、双目视差、单眼聚焦、大脑补充。
而在现有的VR设备里,「单眼聚焦」的机制失效,因此「深度信息」的获取机制,按照优先级从高到低排列有:
(1)双目汇聚(2)双目视差(3)大脑补充
VR眼镜输出的左右两幅画面是有视差的,我们在观看时,
(1)首先人眼通过「双目汇聚」进行定点测距,得到注视点的绝对深度信息。
这一过程称为「对差」,它确定一个深度固定的「零差面」。
(2)然后再通过「双目视差」进行定面测距,评估所有双像的相对深度信息。
(3)最后所有单像和双像都在大脑内进行融合,并通过「大脑补充」添加基于「仿射、遮挡、光影、纹理、经验」的额外深度信息,最终形成一个完整视野的「立体视觉」。

其中,「双目汇聚」和「双目视差」属于人体对「深度信息」的生理感知,也就是硬件测量。
而「大脑补充」属于人体对「深度信息」的心理感知,也就是软件估计。
而「VR沉浸感」的奥秘就在于,借助VR,人体可以硬解出一维「深度信息」。
这个硬解的过程是自动化的,是身体下意识完成的。
就像在现实世界里,我拿个东西戳向你的眼睛,你可能根本没反应过来发生了什么,身体就自动躲开了。
因为大脑基于「双目视差」自动解算了深度信息,察觉到可能有危险的东西靠近,于是执行了躲避。
这种下意识处理的「深度信息」在日常生活里无处不在,因为它会自动发生所以反而被人们忽略了。
在现实里妹子突然凑得很近的话,我一瞬间会容易心跳加速和脸红,但如果隔着手机屏幕,那么我可能就有点无动于衷。
所以这就解释了为什么有些人会痴迷于VR社交。
因为在VR里,我们可以传递这种在现实里大脑会自动硬解的深度信息,而传统的2D屏幕无法输出这种硬解的深度信息。
但其实这种能硬解的深度信息,在现实里是无处不在、且不可或缺的,我们像呼吸一样熟悉它。
4. 深度信息开始流动
事实上到这里我们才能明白VR眼镜的本质是什么。
VR眼镜的本质是可以输出「深度信息」的「双目显示器」。
它输出「深度信息」的方式是,将「深度信息」编码进带有「双目视差」的左右两幅图像里。
在VR眼镜里的画面,不管是建模的还是实拍的,不管是多少DOF的。
最终都会渲染成左右两幅2D的图像,在2块2D的液晶显示屏上显示,对人的左右双眼分别输出。
因此VR游戏和普通的3D游戏相比,其实并没有非常本质的区别。
只是说,普通游戏用1个虚拟摄像机渲染1幅2D的画面交给1块2D的屏幕显示,而VR游戏同时用2个虚拟摄像机模拟双眼渲染带有视差的画面,交给2块2D屏幕分开显示。

从这个角度来看,VR游戏也不过只是一种实时拍摄的「全景视频」。
只不过这个「全景视频」的虚拟双目摄像机,是由玩家自己实时操控的。
而在理解了VR的核心是「输出深度信息」之后,我们才能够知道VR的价值是什么。
在信息时代,信息的传递极为重要。
而VR的价值就在于,它是当前为数不多可以传递「深度信息」的设备。
这个「深度信息」可以是现实世界的深度信息,也可以是虚拟世界的深度信息。
而在我看来,最重要的是现实世界的深度信息。
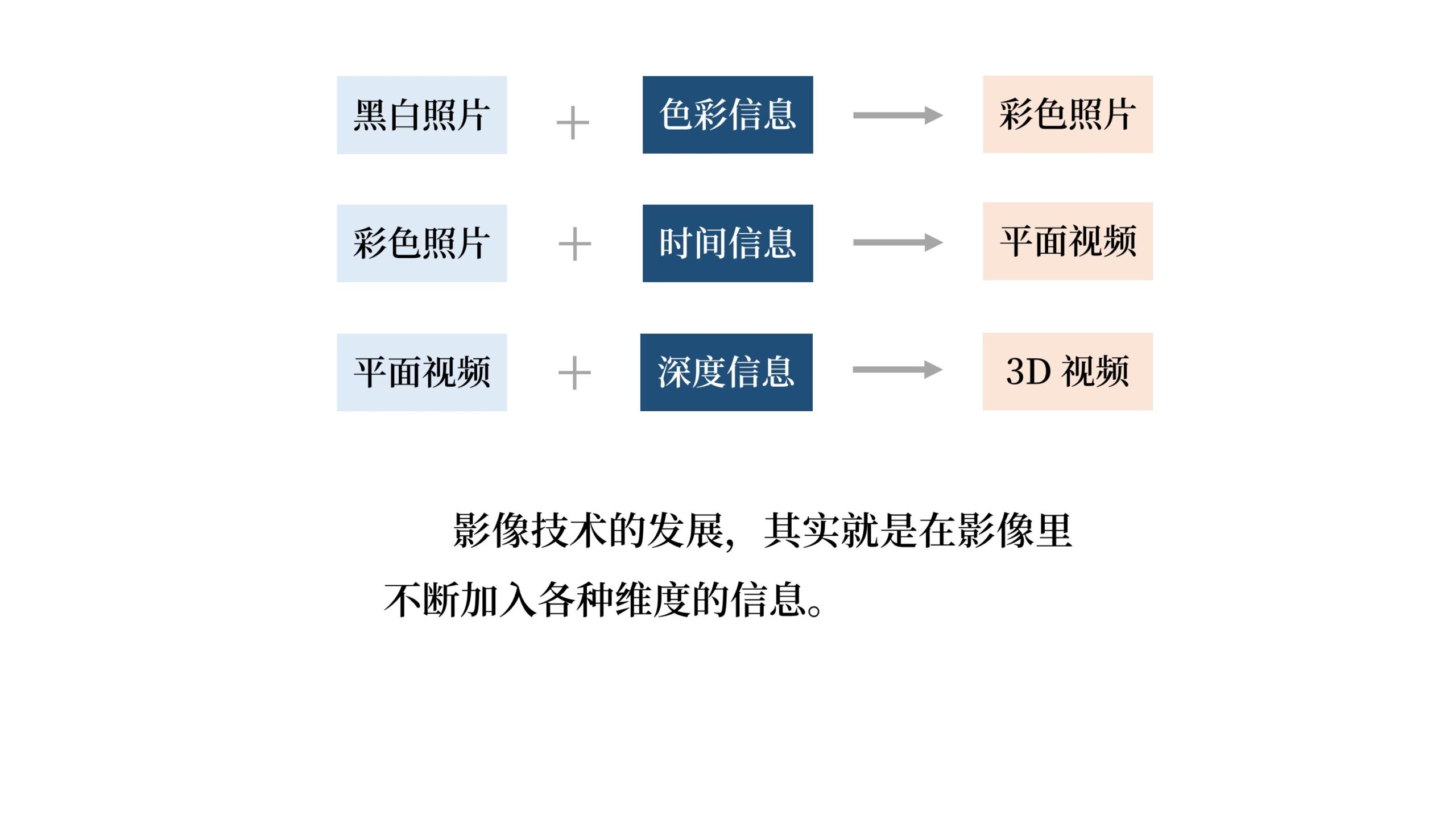
影像技术的发展,其实就是在影像里不断加入各种维度的信息。
黑白照片加入「色彩信息」之后成为彩色照片。
彩色照片加入「时间信息」之后成为平面视频。
平面视频加入「深度信息」之后成为3D视频。
信息的维度总是在不断地增加。
人类总是贪婪地索取着更多更快的信息,永不满足。
而科学技术也总会向着促使信息流动得更快更多的方向发展。
十多年前,电视行业想要往3D视频方向发展,遭遇了挫折。
实际上从信息传递的角度来说这是合理的,只是行业在具体的技术细节上出现错误。
3D电视并不是一个适合传递深度信息的设备,VR才是合适的。
因为非标的「平面3D视频」并不符合人眼识别深度信息的生理机制。
而能够标准化的「球面3D视频」才符合人眼的生理机制,最终能够输出符合现实世界的有效的深度信息。
那么从PICO 4开始,我到底看到了什么呢?
我看到了,现实世界的「深度信息」开始流动起来了。
当世界上全是黑白电视的时候,第一个看到彩色电视的人,他一定会与现在的我同样兴奋。
他一定也会感受到,现实世界的「色彩信息」要开始流动起来了。
那么现在,现实世界里静止着的,又无处不在的深度信息,也要开始流动起来了。
这就是我所看到的,VR最大的价值。
那这一期里,我们回答了2个最基础的问题。
(1)为何VR沉浸感的奥秘是深度信息。
(2)人眼如何通过双目视差硬解深度信息。
实际上它们也引出了更多的问题,有许多的细枝末节需要重新审视。
并且我也很想用更直观的方式去展示「双目视差」的机制。
对它的理解会影响我们后续在「双目VR摄影」上的操作。
但到这里视频已经很长了,所以【双目VR摄影】系列的【V1】就先到这里。
我是HW君,我们下期再见。
(本章节完)
By HW君 @ 2023-02-13
摄影时候如果两个摄像头是平行的,摄像过程应该无法模拟双目汇聚吧?此时vr中用人眼观看,是不是也需要尽量模拟双目平视远方?那可以不可以理解成本文中提到的单眼聚焦、双目汇聚在vr中似乎都是失效的,vr目前实现的只是利用大脑根据双目视差去感知相对深度。
(1)摄像过程不需要模拟双目汇聚,只需要平行记录;(2)汇聚的永远是人眼,而相机、图像都不需要做所谓的汇聚;(3)VR显示中单眼聚焦失效,双目汇聚和双目视差正常工作
我可以这样理解吗:摄影拍摄出来的有视差的图像,就像是文中提到的红蓝两根手指。双目汇聚的作用,是让大脑自动对齐视差图的过程(类似于文中调节红蓝图像的过程),对齐后就有了【零差面】,在用双目视差机制以零差面为分界形成正负差区,以此构建深度的相对关系。
这样感觉能比较好的解释“摄像过程不需要模拟双目汇聚,只需要平行记录”是因为大脑自动根据双目汇聚定义【零差面】
这样理解没问题
写得很棒的VR科普文,概念讲解得很清晰
请问 一些 英文的图表 有论文出处吗
没有特殊说明的话,一般引用的是开头提到的这2本书:
《Handbook of Optical Systems, Volume 4_ Survey of Optical Instruments》WILEY-VCH
《应用光学》第3版-张以谟